Kafka-Architect
内容列表
kafka引入
AKF原则
kafka架构
代码演示
可靠性保证
kafka引入
kafka是什么?
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafka is an event streaming platform used to collect, process, store, and integrate data at scale. It has numerous use cases including distributed streaming, stream processing, data integration, and pub/sub messaging.
重点:不只是分布式消息中间件,还是分布式流式消息(事件)处理平台
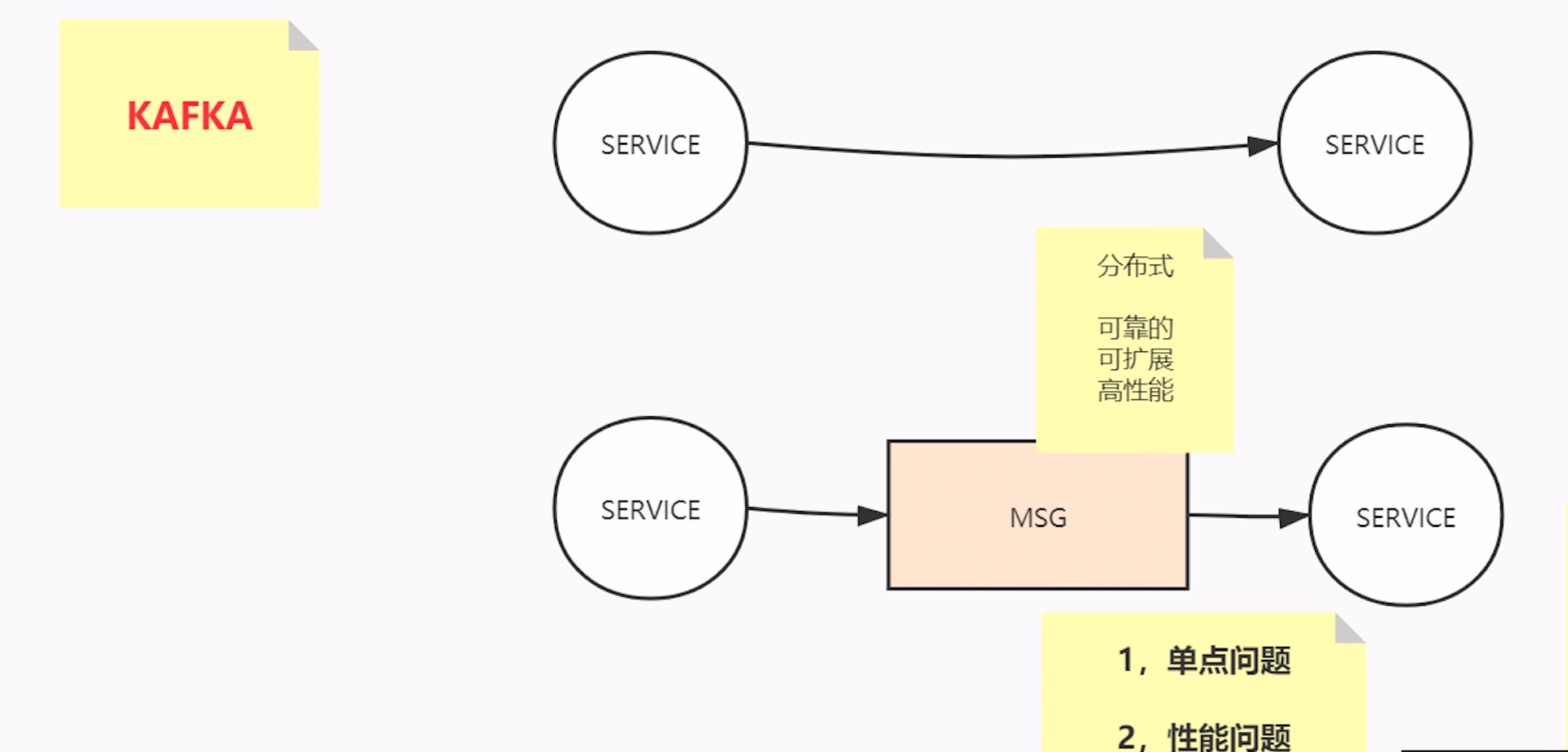
单体到分布式,引入的问题:可靠性、可扩展性、高性能
AKF原则
AKF 立方体也叫做scala cube,它在《The Art of Scalability》一书中被首次提出,旨在提供一个系统化的扩展思路。AKF 把系统扩展分为以下三个维度:
- X 轴:直接水平复制应用进程来扩展系统。(比如单体服务,但部署时一发动全身)
- Y 轴:将功能拆分出来扩展系统。(拆分微服务,但好的业务迟早会遇见数据瓶颈)
- Z 轴:基于用户信息扩展系统。(数据分区,比如分库分表)
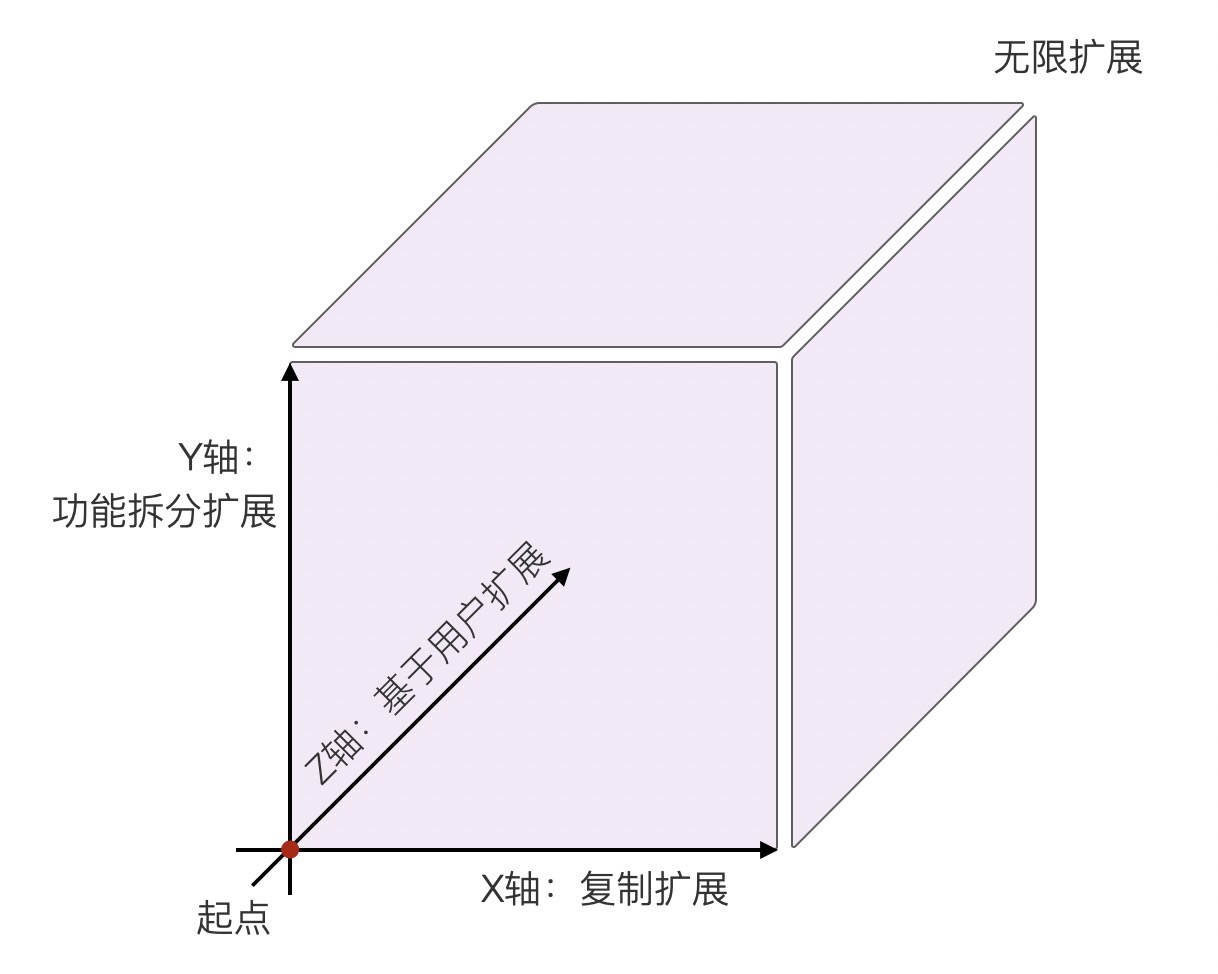
Kafka AKF分析
x轴,对parttion进行副本备份,副本(理论上可以读写分离,但容易出现一致性问题,干脆只能在主P上进行读写)
y轴:topic,不同的业务使用不同topic
z轴:partiton,对无关的数据打散到不同的分片,分而治之。将相关的数据按顺序聚合到同一个分片
Kafka数据处理思路
无关的数据,必然分治——>无关的数据就分散到不同的分区里,以追求并发并行
有关的数据,聚合——> 有关的数据,一定要按原有顺序发送到同一分区里
分区内部有序,分区外部无序
kafka架构
核心组件:Zookeeper、Broker、Topic、Partition、Producer、Consumer(group)
Zookeeper
单机管理->主从集群 分布式协调,zk不用于存储(相当于服务网关,负责路由转发)
旧版本
producer是通过zookeeper获取集群节点信息的,zk除了是个协调以外,还是个存储DB,offset是维护在zookeeper当中
新老版本的区别
角色之间通信,producer和consumer面向的是broker,在业务层次上不再依赖zookeeper(减少zk的负载),只是个协调
元数据Metadata:topic,partition,broker
kafka架构图
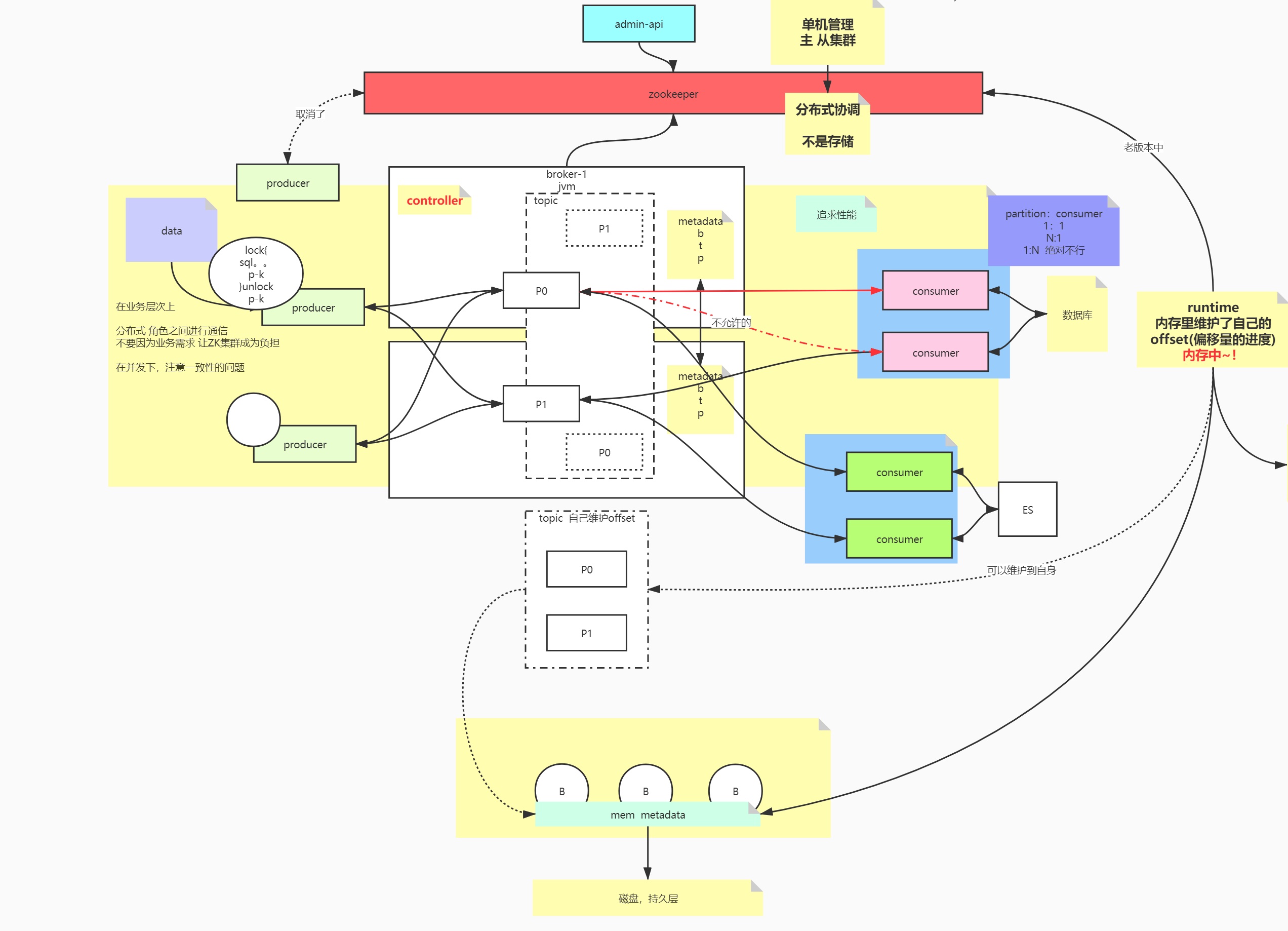
核心组件的关系
broker与zookeeper的关系?
broker与partition的关系?
创建一个topic的过程
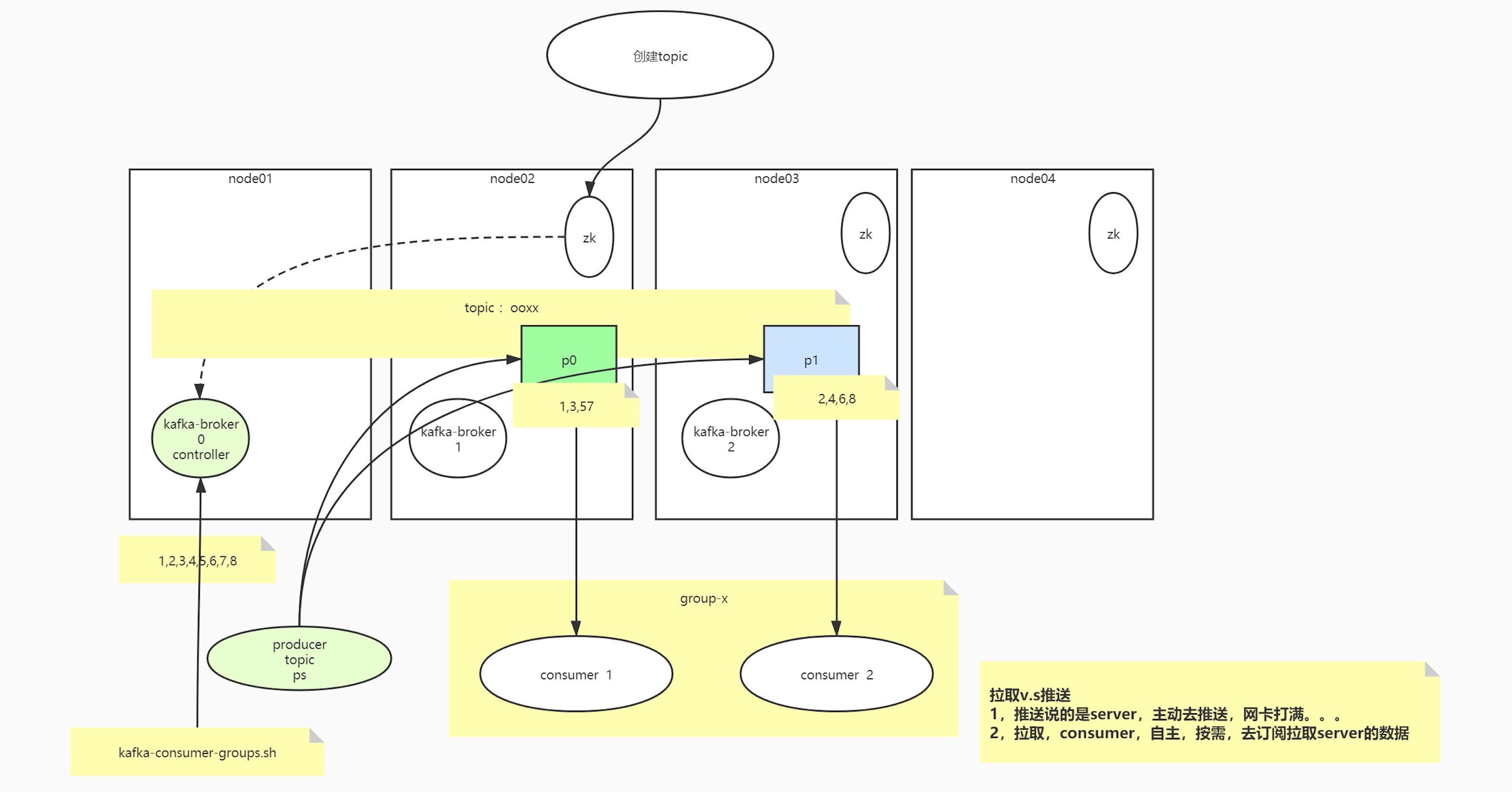
Producer
在并发情况下,注意一致性(顺序性保证)的问题
lock() {
sql
producer.produce()
} unlock();
生产的数据保存在哪里?
kafka的broker的partition里
Consumer
consumer与patition的关系:1:n/ 1:1
思考,consumer与patition的关系n:1可不可以?
破坏有序性
group
不同业务组之间,需要消费同一topic的数据,可以使用不同的group
在单一的使用场景下,先要保证,即便追求性能,用多个consumer,应该注意,不能一个分区由多个consumer消费
数据的重复利用是站在group上
offset
比如consumer重启,会不会导致数据重复消费和丢失,围绕的是消费的进度offset
起初consumer在runtime里维护自身的consumer,旧版本的offset是通过consumer与zookeeper通信维护的
新版kafka能自己维护offset,维护在topic当中,consumer->broker(runtime)->mem metadata->磁盘,持久层
offset的两种提交方式
-
自动提交:每间隔5s,先处理业务逻辑,异步提交offset,重复消费
-
手动提交:处理业务逻辑,同步提交offset
自动异步提交时(默认每5s提交一次),导致的问题?
- 重复消费&消息丢失
- 场景
- 还没到时间,挂了,没提交,重起一个consumer,参照offset的时候,会重复消费。
- 一个批次的数据还没写数据库成功,但是这个批次的offset被异步提交了,挂了,重起一个consumer,参照offset的时候,会导致消息丢失。
代码演示
实战
生产者消费者代码
可靠性保证
可靠性是系统的⼀个属性,⽽不是⼀个独⽴的组件,所以在讨论 Kafka 的可靠性保证时,还是要从系统的整体出发。
可靠性保证
只有当消息被写⼊分区的所有同步副本时(但不⼀定要写⼊磁盘),它才被认为是“已提交”的。
broker配置
broker 有 3 个配置参数会影响 Kafka 消息存储的可靠性。
复制系数
replication.factor,主题级别的配置参数,因为 Kafka 的默认复制系数就是 3——不过⽤户可以修改它。即使是在主题创建之后,也可以通过新增或移除副本来改变复制系数。
如果复制系数为 N,那么在 N-1 个 broker 失效的情况下,仍然能够从主题读取数据或向主题写⼊数 据。所以,更⾼的复制系数会带来更⾼的可⽤性、可靠性和更少的故障。另⼀⽅⾯,复制系数 N 需要 ⾄少 N 个 broker,⽽且会有 N 个数据副本,也就是说它们会占⽤ N 倍的磁盘空间。我们⼀般会在可⽤性和存储硬件之间作出权衡。
副本的分布也很重要。默认情况下,Kafka 会确保分区的每个副本被放在不同的 broker 上。
不完全的⾸领选举
unclean.leader.election.enable只能在 broker 级别(实际上是在集群范围内)进⾏配置,它的默认值是 true。
我们之前提到过,当分区⾸领不可⽤时,⼀个同步副本会被选为新⾸领。如果在选举过程中没有丢失数据,也就是说提交的数据同时存在于所有的同步副本上,那么这个选举就是“完全”的。 但如果在⾸领不可⽤时其他副本都是不同步的,我们该怎么办呢?
简⽽⾔之,如果我们允许不同步的副本成为⾸领,那么就要承担丢失数据和出现数据不⼀致的⻛险。 如果不允许它们成为⾸领,那么就要接受较低的可⽤性,因为我们必须等待原先的⾸领恢复到可⽤状态。
如果把 unclean.leader.election.enable 设为 true,就是允许不同步的副本成为⾸领(也就 是“不完全的选举”),那么我们将⾯临丢失消息的⻛险。如果把这个参数设为 false,就要等待原先的⾸领重新上线,从⽽降低了可⽤性。
两种场景:银行系统,信用卡支付事务/实时点击流分析系统
最少同步副本
在主题级别和 broker 级别上,这个参数都叫 min.insync.replicas。
根据 Kafka 对可靠性保证的定义,消息只有在被写⼊到所有同步副本之后才被认为是已提交的。
对于 ⼀个包含 3 个副本的主题,如果 min.insync.replicas 被设为 2,那么⾄少要存在两个同步副本 才能向分区写⼊数据。 如果 3 个副本都是同步的,或者其中⼀个副本变为不可⽤,都不会有什么问题。不过,如果有两个副 本变为不可⽤,那么 broker 就会停⽌接受⽣产者的请求。尝试发送数据的⽣产者会收到 NotEnoughReplicasException 异常。消费者仍然可以继续读取已有的数据。实际上,如果使⽤ 这样的配置,那么当只剩下⼀个同步副本时,它就变成只读了,这是为了避免在发⽣不完全选举时数 据的写⼊和读取出现⾮预期的⾏为。为了从只读状态中恢复,必须让两个不可⽤分区中的⼀个重新变 为可⽤的(⽐如重启 broker),并等待它变为同步的。
在可靠的系统⾥使⽤⽣产者
- 根据可靠性需求配置恰当的 acks 值。
- 在参数配置和代码⾥正确处理错误。
acks(0,1,all)
⼀般情况下,如果你的⽬标是不丢失任何消息,那么最好让⽣产者在遇到可重试错误时能够保持重试。
重试发送⼀个已经失败的消息会带来⼀些⻛险,如果两个消息都写⼊成功,会导致消息重 复。重试和恰当的错误处理可以保证每个消息“⾄少被保存⼀次”,但当前 的 Kafka 版本(0.10.0)⽆法保证每个消息“只被保存⼀次”。
在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture)或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
所谓的消息交付可靠性保障,是指 Kafka 对 Producer 和 Consumer 要处理的消息提供什么样的承诺。常见的承诺有以下三种:
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
使⽤⽣产者内置的重试机制可以在不造成消息丢失的情况下轻松地处理⼤部分错误,不过对于开发⼈员来说,仍然需要处理其他类型的错误,包括:
- 不可重试的 broker 错误,例如消息⼤⼩错误、认证错误等;
- 在消息发送之前发⽣的错误,例如序列化错误;
- 在⽣产者达到重试次数上限时或者在消息占⽤的内存达到上限时发⽣的错误
- 丢弃“不合法的消息”?
- 把错误记录下来?
- 把这些消息保存在本地 磁盘上?
- 回调另⼀个应⽤程序?
具体使⽤哪⼀种逻辑要根据具体的架构来决定。只要记住,如果错误处理只是为了重试发送消息,那么最好还是使⽤⽣产者内置的重试机制。
在可靠的系统⾥使⽤消费者
group.id:消费者组id
auto.offset.reset:(earliest/latest)
enable.auto.commit:(自动提交/手动提交)
auto.commit.interval.ms:自动提交的时间间隔
手动提交offset
错误重试,超过重试次数,就写入三方组件
仅⼀次传递:幂等性写⼊
总结
可靠性并不只是 Kafka 单⽅⾯的事情,我们应该从整个系统层⾯来考虑 可靠性问题,包括应⽤程序的架构、⽣产者和消费者 API 的使⽤⽅式、⽣产者和消费者的配置、主题 的配置以及 broker 的配置。
系统的可靠性需要在许多⽅⾯作出权衡,⽐如复杂性、性能、可⽤性和 磁盘空间的使⽤。掌握 Kafka 的各种配置和常⽤模式,对使⽤场景的需求做到⼼中有数,你就可以在 应⽤程序和 Kafka 的可靠性程度以及各种权衡之间作出更好的选择。