简介
我的技术笔记:Inspired by lvt4j and reference from.
本博客使用mdbook+github page进行搭建,相关语法可参考 mdbook官方指南
笔记已经推送到 个人github仓库
学习方向
基础学习: 通读官方文档,熟悉API.
拔高学习: 源码核心设计,接口,机制,流程,抽象等.
技术关键字
Kafka: Streaming Processing Platform
Akka:Reactive Architecture
SMACK: Spark/Mesos/Akka/Cassandra/Kafka
学习进度
| 技术 | 进度 |
|---|---|
| Akka | https://doc.akka.io/docs/akka/current/mailboxes.html |
| Es | https://www.elastic.co/guide/cn/elasticsearch/guide/current/full-text-search.html |
| Kafka | https://developer.confluent.io/patterns/ |
| Spring | https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#beans-factory-autowire |
| Redis | https://redis.io/docs/getting-started/ |
| Mysql | 尚未开始 |
技术栈
Coding
admin
common-design
需要给业务层提供通用类库,该以怎么样的方式提供?通常有以下几种方式:
1.类似于apache common这种模式,应用层调用库。
2.类似于Spring boot stater+auto-configuration这种模式。
3.类似于IOC/框架模式/模板(XXXTemplate)/策略(回调)模式,框架调用应用层代码。典型的如JDBCTemplate.
4.类似于普通Spring模式,提供库,并且暴露配置且提供默认配置,由应用层自定义设置。
common-elasticsearch
Kafka学习笔记
学习笔记
1. kafka前瞻—架构维度
2. kafka安装以及常用的命令
3. 基础开发及消费者提交维护offset不同粒度
4. ISR,OSR,AR,LW,HW,LEO,ACK原理理论
书籍
1. chatGPT写的一篇《Kafka权威指南》总结
2. 《Kafka权威指南》笔记
地址
git项目地址
Kafka学习笔记
1. kafka前瞻—架构维度
kafka是什么?分布式消息中间件,分布式流式消息(事件)处理平台
服务——>服务
网络到分布式
- 单点问题 2. 性能问题
分布式:一致性,可靠性,可扩展性
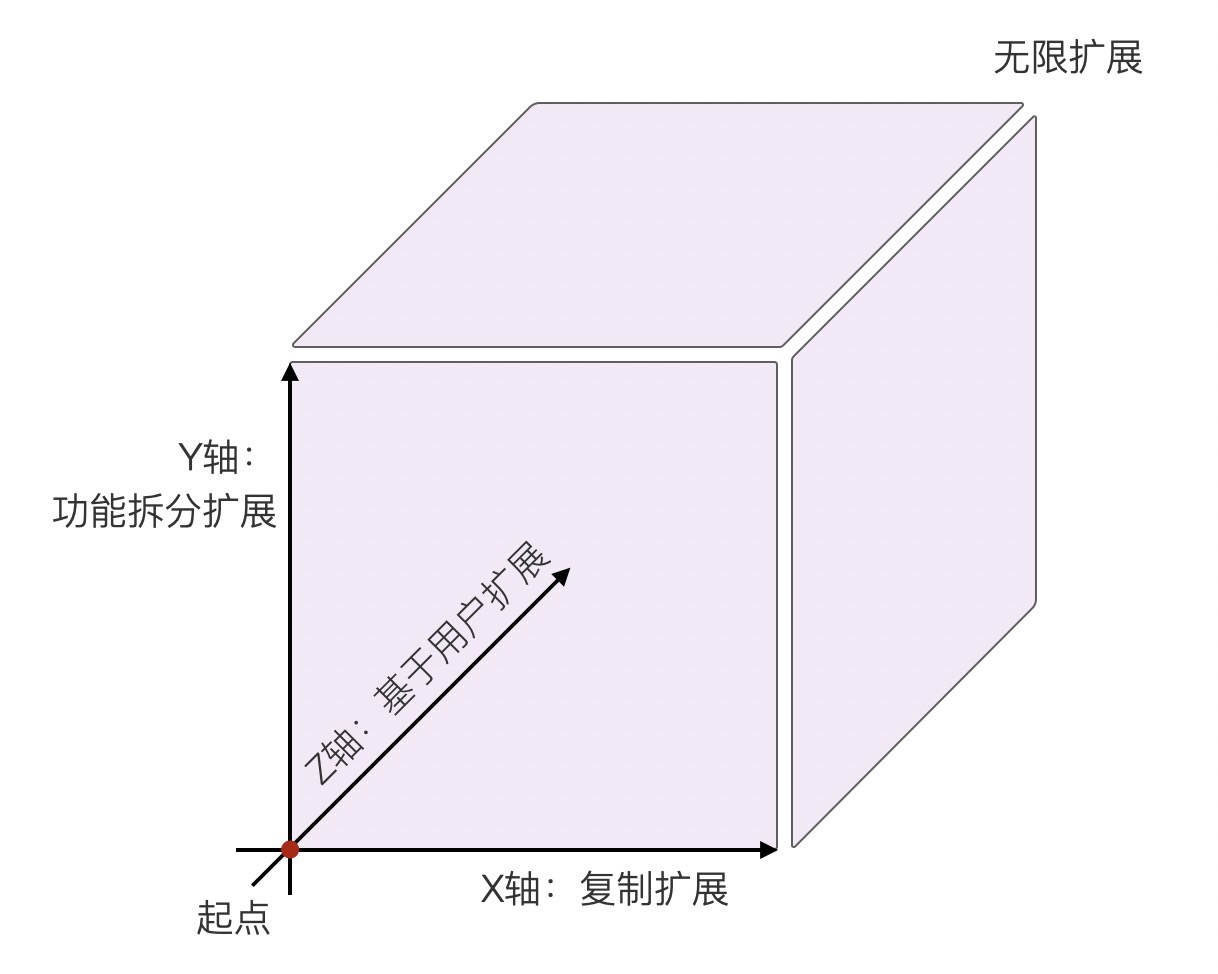
AKF
x-高可用 横向扩展,水平复制(没解决的问题:一发动全身)
y-业务功能划分 功能分解扩展,比如微服务(好的业务迟早会遇见数据瓶颈)
z-数据分区,比如分库分表
数据处理
大数据
无关的数据 必然分治——>无关的数据就分散到不同的分区里,以追求并发并行
有关的数据 聚合——> 有关的数据,一定要按原有顺序发送到同一分区里
分区内部有序,分区外部无序
Kafka AKF分析
x轴,对parttion进行副本备份,副本(理论上可以读写分离,但容易出现一致性问题,干脆只能在主P上进行读写)
y轴:topic,不同的业务使用不同topic
z轴:partiton,对无关的数据打散到不同的分片,分而治之。将相关的数据按顺序聚合到同一个分片
Zookeeper
单机管理->主从集群 分布式协调,zk不用于存储
broker与partition的关系?
broker与zookeeper的关系?
controller
Metadata:topic,partition,broker
旧版本:producer是通过zookeeper获取集群节点信息的
新老版本的区别:角色之间通信,在业务层次上不再依赖zookeeper(减少zk的负载)
Producer
在并发情况下,注意一致性(顺序性保证)的问题
lock() {
sql
producer.produce()
} unlock();
数据保存在哪里?
kafka的broker的partition里
Consumer
consumer与patition的关系:1:n/ 1:1
思考,consumer与patition的关系n:1可不可以? 破坏有序性
group
不同业务组之间,需要消费同一topic的数据,可以使用不同的group
在单一的使用场景下,先要保证,即便追求性能,用多个consumer,应该注意,不能一个分区由多个consumer消费
数据的重复利用是站在group上
offset
比如consumer重启,会不会导致数据重复消费和丢失,围绕的是消费的进度offset
起初consumer在runtime里维护自身的consumer
旧版本的offset是通过consumer与zookeeper通信维护的
新版kafka能自己维护offset
offset持久化节奏,频率,先后?
两大问题:
- 丢失
- 重复消费
异步的:每间隔5s,先处理业务逻辑,异步提交offset,重复消费
同步的:处理业务逻辑,同步提交offset
Consume流程没处理好,提交offset在业务逻辑处理之前,导致丢失
hbase,es,myisam顺序写
新版offset的维护
consumer->broker(runtime)->mem metadata->磁盘,持久层
总结
- 本节课从分布式AFK角度,分析了kafka作为一个分布式消息中间件(高可用,高扩展),从架构角度对xyz轴分析,分别对应由副本,partition,topic的出现。
- 同时既然作为一个集群,就需要有一个协调者,引入了zookeeper,新旧版本的kafka对zookeeper这块进行了比较大的升级。
- zookeeper管理的本质其实是tomcat进程,逻辑意义是broker,里面会有一个controller(主)的概念
- 为了消息的顺序性消费,引入了producer和consumer,以及从架构角度如何保证消息顺序消费,不重复消费,以及消息丢失等问题。
- 为了解决丢失和重复消费的问题,引入了offset消息消费进度的概念,以及放在哪里进行维护比较好(zookeeper?kafka?三方比如redis/mysql)
思考
- Redis哨兵很像 kafka 集群中的 zookeeper 的功能
- 微服务AKF拆分,涉及的三种集群模式:主主,主从,主备
- 前两种比较容易理解,最后一种备节点不提供读写,随时顶替上去。
Kafka学习笔记
2. kafka安装以及常用的命令
zookeeper的安装
-
brew方式安装
- 参考博客
- 启动zookeeper: zookeeper alongso_pro$ zkServer
- 查看zookeeper的状态: zookeeper alongso_pro$ zkCli
-
解压缩方式安装:
- 参考博客
- zookeeper安装目录:/usr/local/myapp/zookeeper-3.4.12
- 进入zookeeper安装目录,启动zookeeper:sudo ./bin/zkServer.sh start
- 停止zookeeper:sudo ./bin/zkServer.sh stop
kafka的安装
- brew方式安装
- 进入kafka安装目录,启动zookeeper:
- bin/zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
- 启动kafka:
- bin/kafka-server-start /usr/local/etc/kafka/server.properties
- 进入kafka安装目录,启动zookeeper:
- 解压缩方式安装:
- 解压缩方式安装
- 进入指定的文件(安装目录)创建logs文件夹,并且赋予用户能写 的权限(将/usr/local/myapp/kafka下的文件都赋予)
- 启动zookeeper:
- kafka alongso_pro$ ./bin/zookeeper-server-start.sh /usr/local/myapp/kafka/config/zookeeper.properties &
- 启动kafka:
- kafka alongso_pro$ ./bin/kafka-server-start.sh /usr/local/myapp/kafka/config/server.properties &
- 遇到的问题
- 启动消费者的时候报错:Connection to node -1 could not be established. Broker may not be available.
- zookeeper启动的时候报错 java.io.IOException: No snapshot found, but there are log entries. Something is broken!
- 解压缩方式安装
kafka常用命令
-- 低于kafka2.2版本的所有的命令需要依赖zookeeper节点,不支持--bootstrap-server命令
-- 给kafka创建topic:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
- –create 创建主题命令
- –zookeeper localhost:2181 指定zookeeper
- –replication-factor 1 指定副本个数
- –partitions 1 指定分区个数
- –topic test 主题名称为“test”
-- 查看topic list
- ./bin/kafka-topics.sh --list --zookeeper localhost:2181
-- 打开一个窗口输入命令创建一个生产者:
- ./bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
-- 高于2.2版本,支持--bootstrap-server命令
-- topic创建
./bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 2 --topic test2
-- 查看topic
./bin/kafka-topics.sh --describe --bootstrap-server 127.0.0.1:9092 --topic test2
-- 查看消费者组消费的进度offset
./bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group consumer0 --describe
-- 消费消息
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning
-- 生产消息
./bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic test
-- 查看list
./bin/kafka-topics.sh --list --bootstrap-server 127.0.0.1:9092
-- 生产&发送键-值对消息
./bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic test --property parse.key=true
-- 消费&打印键-值对消息
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --property print.key=true
参考资料
topic+partition消费逻辑
partition
分区:桶
如果没有顺序上的约束的话:水平扩展
消息V
一旦消息(消息很多,但是消息种类一定很多),而且需要同一类消息的有序性
消息是KV,相同的key一定去打到一个分区里
Broker会保证producer同key(类型)消息的顺序
一个分区可能有不同的key,且不同的key是交叉的,相同的key在一个分区里没有排列在一起。
拉取VS推送
推送:说的是server,主动去推送,网卡打满
拉取:consumer,自主,按需,去订阅拉取server的数据
拉取粒度
如何拉取
-
Kafka consumer以什么粒度拉取消息
出于性能考虑,每次IO会批量拉取数据
如何维护
-
Kafka consumer以什么粒度更新&持久化offset?
单线程:一条一条处理的时候,按顺序处理的时候,来更新offset,速度比较慢,硬件资源浪费
1-1多线程:offset维护?按条还是按批次?
什么情况下多线程的优势发挥到极致?具备隔离性
多线程的情况下,要加如记录级的判定顺序,决策更新谁的offset
2多线程:流式计算,充分利用线程
批次(如何保证顺序处理)
- consumer拉取到消息用多线程还是单线程去处理?
- Offset如何维护?
consume使用单线程与多线程的利弊
单线程:
按顺序,单条处理,offset就是递增的,无论对db,offset频率,成本有点高,CPU,网卡,资源浪费,粒度比较细
流式的多线程:
能多线程的多线程,但是,将整个批次的事务环节交给一个线程,做到这个批次,要么成功,要么失败,减少对DB的压力,和offset频率的压力,更多的去利用cpu和网卡硬件资源,粒度比较粗
Kafka学习笔记
3. 基础开发及消费者提交维护offset不同粒度
编码实现kafka生产与消费消息
-
零拷贝
-
producer面向的是broker
-
consumer消费消息依赖于消费者组
-
kafka自己存储数据,指定消息的offset
-
自动异步提交时(默认每5s提交一次),导致的问题?
- 重复消费&消息丢失
- 场景
- 还没到时间,挂了,没提交,重起一个consumer,参照offset的时候,会重复消费
- 一个批次的数据还没写数据库成功,但是这个批次的offset被异步提交了,挂了,重起一个consumer,参照offset的时候,会导致消息丢失。
-
指定一次拉取的最多条数
-
指定拉取一次的超时时间
-
消费的时候可以指定开始消费的下标
- latest和earliest区别
- latest—表示一个新的消费者组,刚启动时不消费历史数据(即之前已经被别的组消费的数据)
- earliest—表示新消费者组启动之后,会开始重新消费历史数据
- latest和earliest区别
-
分区分配:一个消费者可以消费同一个topic多个分区的数据
-
手动提交offset的配置,按照分区进行处理消息
实践
- 单节点kafka只能有一个副本,可以有多个分区
- kafka开启自动提交,默认是每隔5s自动提交一次offset
- latest和earliest区别
- earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
- latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
- 结论:提交过offset,latest和earliest没有区别,但是在没有提交offset情况下,用latest直接会导致无法读取旧数据。
生产者代码
-
生产者架构图
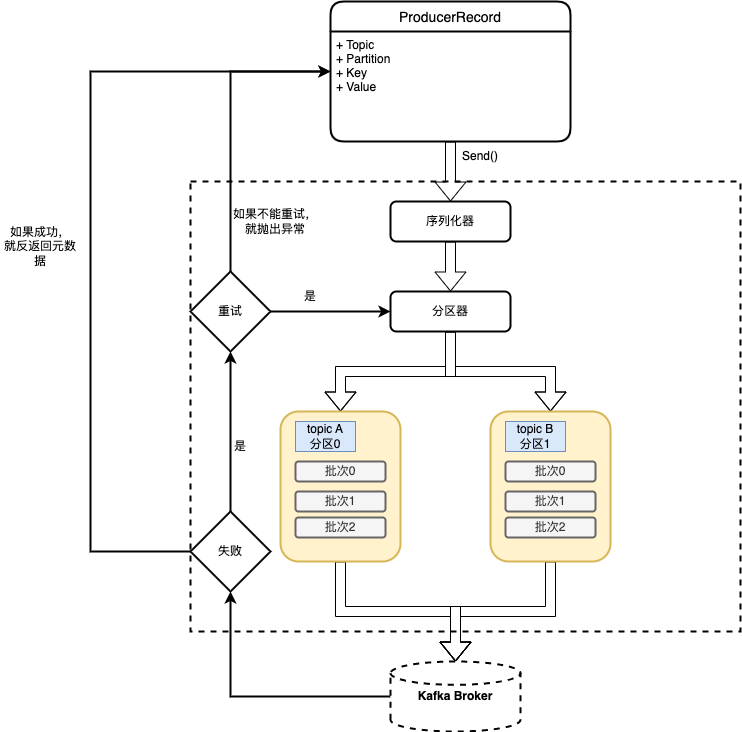
-
创建Kafka生产者
- boostrap.servers
- key.serializer
- value.serializer
-
代码示例
package com.focus.kafka.produce; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import org.junit.jupiter.api.Test; import java.util.Properties; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class ProducerTest { // ./bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 2 --topic test2 @Test public void producer() throws ExecutionException, InterruptedException { String topic = "test2"; Properties p = new Properties(); p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //kafka 持久化数据的MQ 数据-> byte[],不会对数据进行干预,双方要约定编解码 //kafka是一个app::使用零拷贝 sendfile 系统调用实现快速数据消费 p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); p.setProperty(ProducerConfig.ACKS_CONFIG, "-1"); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p); //现在的producer就是一个提供者,面向的其实是broker,虽然在使用的时候我们期望把数据打入topic /* test2,2partition,三种商品,每种商品有线性的3个ID,相同的商品最好去到一个分区里 */ while (true) { for (int i = 0; i < 3; i++) { for (int j = 0; j < 3; j++) { ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item" + j, "val" + i); // Future<RecordMetadata> send = producer.send(record); Future<RecordMetadata> send = producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception != null) { exception.printStackTrace(); } } }); RecordMetadata rm = send.get(); int partition = rm.partition(); long offset = rm.offset(); System.out.println("key: " + record.key() + " val: " + record.value() + " partition: " + partition + " offset: " + offset); } } } } /** * key: item0 val: val0 partition: 1 offset: 0 * key: item1 val: val0 partition: 0 offset: 0 * key: item2 val: val0 partition: 1 offset: 1 * key: item0 val: val1 partition: 1 offset: 2 * key: item1 val: val1 partition: 0 offset: 1 * key: item2 val: val1 partition: 1 offset: 3 * key: item0 val: val2 partition: 1 offset: 4 * key: item1 val: val2 partition: 0 offset: 2 * key: item2 val: val2 partition: 1 offset: 5 * key: item0 val: val0 partition: 1 offset: 6 * key: item1 val: val0 partition: 0 offset: 3 * key: item2 val: val0 partition: 1 offset: 7 * key: item0 val: val1 partition: 1 offset: 8 * key: item1 val: val1 partition: 0 offset: 4 * key: item2 val: val1 partition: 1 offset: 9 * key: item0 val: val2 partition: 1 offset: 10 * key: item1 val: val2 partition: 0 offset: 5 * key: item2 val: val2 partition: 1 offset: 11 * key: item0 val: val0 partition: 1 offset: 12 * key: item1 val: val0 partition: 0 offset: 6 * key: item2 val: val0 partition: 1 offset: 13 * key: item0 val: val1 partition: 1 offset: 14 * key: item1 val: val1 partition: 0 offset: 7 * key: item2 val: val1 partition: 1 offset: 15 * key: item0 val: val2 partition: 1 offset: 16 * key: item1 val: val2 partition: 0 offset: 8 * key: item2 val: val2 partition: 1 offset: 17 * key: item0 val: val0 partition: 1 offset: 18 * key: item1 val: val0 partition: 0 offset: 9 * key: item2 val: val0 partition: 1 offset: 19 * key: item0 val: val1 partition: 1 offset: 20 * key: item1 val: val1 partition: 0 offset: 10 * key: item2 val: val1 partition: 1 offset: 21 * key: item0 val: val2 partition: 1 offset: 22 * * **/ } -
kafka的分区数据视图
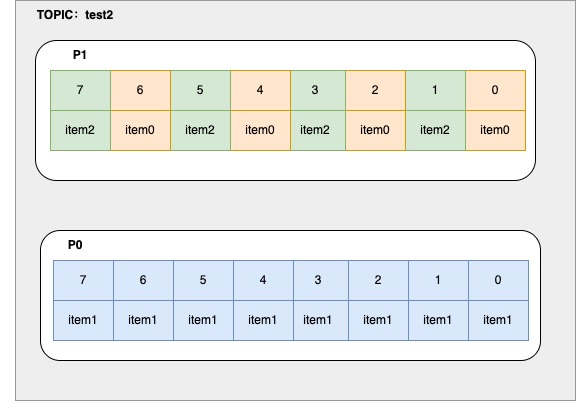
-
发送消息的3种方式
-
发送并忘记:消息可能会被丢失
producer.send(record) -
同步发送:等待kafka返回结果
producer.send(record).get() -
异步发送:设置一个回调函数,记录&处理异常信息,需要实现Callback接口
Future<RecordMetadata> send = producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception != null) { exception.printStackTrace(); } }});
-
-
生产者重要的配置参数
- acks参考:副本机制、同步机制、ISR机制
- acks=0,不会等待任何broker的响应,只是发送,消息丢失了不知道,为了吞吐量优先
- acks=1,集群首领(Leader)副本收到消息,会收到消息成功的响应。如果首领副本崩溃,如果消息还没有被复制到新的首领副本,则消息还是有可能丢失。
- acks=all(-1),所有副本全部收到消息时,生产者才会收到成功的响应
- acks参考:副本机制、同步机制、ISR机制
-
序列化器
- 强烈建议使用通用的序列化框架
-
分区
- 如果key为null,并且使用了默认的分区器,那么记录将被随机发送给主题的分区,分区器使用轮询调度算法将消息均衡分布给分区
- 如果有key的话,会对key进行hash取模(使用kafka自己的哈希算法,即使jdk升级,分区也不会改变)
消费者代码
-
消费者与消费者组
- 对消费者进行横向扩展,kafka消费者从属于消费者组。一个群组里的消费
-
消费者群组与分区再均衡
- 主动再均衡(stop the world)
- 协作再均衡(一部分分区会重新进行分配)
-
群组固定成员
- group.instance.id:固定成员的唯一id
- session.timeout.ms:大概表示的是,当固定成员关闭时,大概多长时间离开群组。如果这个参数设置的足够大,可以避免进行简单的应用程序重启时出发再均衡。又要设置得足够小,以便于出现严重停机时自动重新分配分区。
-
消费者代码
@Test public void consumer0() { /** * ./bin/kafka-topics.sh --list --bootstrap-server 127.0.0.1:9092 **/ //基础配置 Properties p = new Properties(); p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //消费的细节 p.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "consumer2"); //KAKFA IS MQ IS STORAGE p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");//第一次启动,没有offset /** * "What to do when there is no initial offset in Kafka or if the current offset * does not exist any more on the server * (e.g. because that data has been deleted): * <ul> * <li>earliest: automatically reset the offset to the earliest offset * <li>latest: automatically reset the offset to the latest offset</li> * <li>none: throw exception to the consumer if no previous offset is found for the consumer's group</li><li>anything else: throw exception to the consumer.</li> * </ul>"; */ p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");//自动提交时异步提交,丢数据&&重复数据 //一个运行的consumer ,那么自己会维护自己消费进度 //一旦你自动提交,但是是异步的 //1,还没到时间,挂了,没提交,重起一个consuemr,参照offset的时候,会重复消费 //2,一个批次的数据还没写数据库成功,但是这个批次的offset背异步提交了,挂了,重起一个consuemr,参照offset的时候,会丢失消费 p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"5000");//5秒 // p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,""); // POLL 拉取数据,弹性,按需,拉取多少? KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p); //kafka 的consumer会动态负载均衡 consumer.subscribe(Arrays.asList("test3")); while (true) { /** * 常识:如果想多线程处理多分区 * 每poll一次,用一个语义:一个job启动 * 一次job用多线程并行处理分区,且job应该被控制是串行的 * 以上的知识点,其实如果你学过大数据 */ //微批的感觉 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));// 0~n Iterator<ConsumerRecord<String, String>> iter = records.iterator(); while (iter.hasNext()) { //因为一个consuemr可以消费多个分区,但是一个分区只能给一个组里的一个consuemr消费 ConsumerRecord<String, String> record = iter.next(); int partition = record.partition(); long offset = record.offset(); String key = record.key(); String value = record.value(); System.out.println("key: " + record.key() + " val: " + record.value() + " partition: " + partition + " offset: " + offset); } } } -
轮询
- max.poll.interval.ms:消费者poll()方法调用最大间隔时间,如果超过这个值,消费者将被认为已经“死亡”。
-
消费者配置
- fetch.max.wait.ms
- fetch.min.bytes
- fetch.max.bytes
- max.poll.records
- enable.auto.commit
-
提交偏移量
- 自动提交,每次间隔多长时间提交
- 提交当前偏移量:commitSync,同步提交,会发生阻塞。commitSync()将会提交poll()返回的最新偏移量
- 异步提交:commitASync,由于是异步提交,就不能保证先执行的先提交成功,比如偏移量为2000的因为通信原因在偏移量3000提交成功之后,再提交成功,就会出现消息重复消费,该方法支持回调
- 同步和异步
-
再均衡监听器
- ConsumerRebalanceListenner
- onPartitionsAssigned:再平衡已经结束,并且开始拉取消息之前,调用,可以用来找到正确的消费点位(偏移量)
- onPartitionsRevoked:再平衡开始之前,并且消费者停止读取消息之后调用,这里可以用来提交offset,用来记录消费点位。
- ConsumerRebalanceListenner
-
从特定偏移量位置读取记录
- seekToBeginning(),从分区的起始位置读取消息
- seekToEnd(),从分区的末尾位置读取消息
-
消费者退出
-
consumer.close()
-
反序列化器
思考
- offset可以按照什么粒度去维护的?
- 按照分区
- 手动提交的,维护offset的3种方式
- 按记录消费进度同步提交
- 按分区粒度同步提交
- 按当前poll的批次同步提交
- 无论是单线程还是多线程,需要poll的数据处理的事务和offset必须是一致的
Kafka学习笔记
4. ISR,OSR,AR,LW,HW,LEO,ACK原理理论
kafkaIO
零拷贝—找周老师的IO课
sendfile(in, offset,out)
kafka对数据只是发送,没有加工的过程
分区的可靠性(CAP)
要解决一个问题,可能会引入其他问题,比如一致性问题
一致性
- 强一致性
- 所有节点比必须ack
- 最终一致性
- 过半机制
- 弱一致性
- ISR(in-sync replicas同步副本),连通性&活跃性
- OSR(outof-sync replicas不同步副本),超过阈值时间(10s),没有心跳
- AR(Assignes replicas),面向分区的副本集合,创建topic的时候你给出了分区的副本数
- AR=ISR+OSR
- ack=-1的时候,多个broker的消息进度是一致的
- 会与ISR相关的节点进行ack
- tradeoff
- 不要强调磁盘的可靠性,转向异地多机的同步
- 如果拿磁盘做持久化,优先pagecache或者绝对磁盘
- 在多机集群分布式的时候,强一致性,最终一致性(过半,ISR)
- 总结:
- redis,宁可用HA,不用刻意追求AOF的准确性
- 像Kafka,我们追求ack=-1,要求磁盘的可靠性
kafka弹性存储
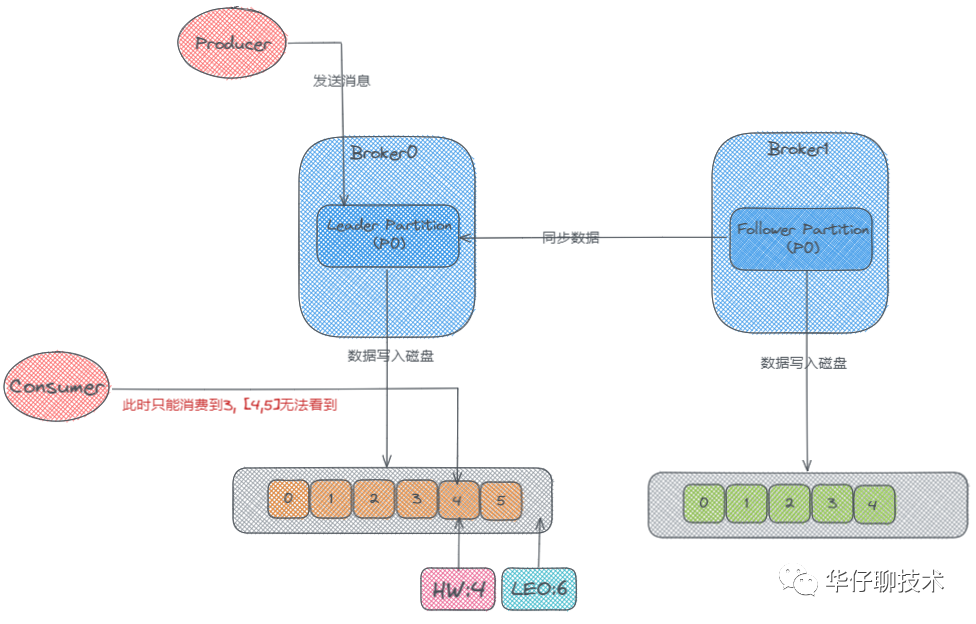
首先这里有两个Broker,也就是两台服务器,然后它们的分区中分别存储了两个 p0 的副本,一个是 Leader,一个是 Follower, 此时生产者开始往 Leader Partition 发送数据,数据最终写到磁盘上的。然后 Follower 会从 Leader那里去同步数据,Follower上的数据也会写到磁盘上。可是 Follower 是先从 Leader 那去同步然后再写入磁盘的,所以它磁盘上面的数据肯定会比 Leader 的那块少一些。
概念
-
LW:Low Watermark 低水位
- 分区中所有已经被成功写入但尚未被消费者消费的最小偏移量,用于跟踪已经消费的消息,管理消息的删除以及控制消费者的位置。
-
HW:High Watermark,高水位
- 副已经被成功写入并且已经被所有 ISR(in-sync replicas)确认的最大偏移量,它用于控制消费者只能消费已经被完全确认的消息,并且用于管理消息的删除。
-
LEO:LogEndOffset,日志末端位移:
- 副本中下一条待写入消息的offset
在 Kafka 中HW高水位的作用主要有2个:
- 用来标识分区下的哪些消息是可以被消费者消费的。
- 协助 Kafka 完成副本数据同步
而LEO一个重要作用就是用来更新HW:
- 如果 Follower 和 Leader 的 LEO 数据同步了, 那么 HW 就可以更新了。
- HW 之前的消息数据对消费者是可见的, 属于 commited 状态, HW 之后的消息数据对消费者是不可见的。
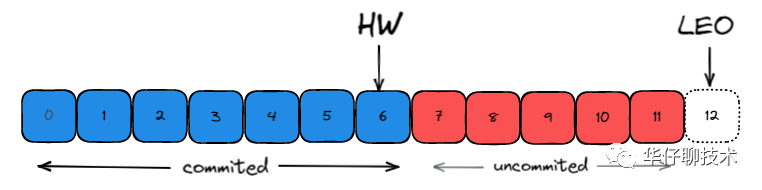
如上图所示: 每个副本会同时维护 HW 与 LEO 值:
-
Leader 保证只有 HW 及其之前的消息,才对消费者是可见的。
-
Follower 宕机后重启时会对其日志截断,只保留 HW 及其之前的日志消息(新版本有改动)
-
对于日志末端位移, 即 Log End Offset (LEO)。它表示副本写入下一条消息的位移值。注意: 数字 12 所在的方框是虚线,说明这个副本当前只有 12 条消息,位移值是从 0 到 11,下一条新消息的位移是 12。显然,介于高水位和 LEO 之间的消息就属于未提交消息。即同一个副本对象,其高水位值不会大于 LEO 值。
-
高水位和 LEO 是副本对象的两个重要属性。Kafka 使用 Leader 副本的高水位来定义所在分区的高水位。即分区的高水位就是其 Leader 副本的高水位。
TradeOff
Keeping track of what has been consumed is, surprisingly, one of the key performance points of a messaging system. Most messaging systems keep metadata about what messages have been consumed on the broker. That is, as a message is handed out to a consumer, the broker either records that fact locally immediately or it may wait for acknowledgement from the consumer. This is a fairly intuitive choice, and indeed for a single machine server it is not clear where else this state could go. Since the data structures used for storage in many messaging systems scale poorly, this is also a pragmatic choice--since the broker knows what is consumed it can immediately delete it, keeping the data size small.
What is perhaps not obvious is that getting the broker and consumer to come into agreement about what has been consumed is not a trivial problem. If the broker records a message as consumed immediately every time it is handed out over the network, then if the consumer fails to process the message (say because it crashes or the request times out or whatever) that message will be lost. To solve this problem, many messaging systems add an acknowledgement feature which means that messages are only marked as sent not consumed when they are sent; the broker waits for a specific acknowledgement from the consumer to record the message as consumed. This strategy fixes the problem of losing messages, but creates new problems. First of all, if the consumer processes the message but fails before it can send an acknowledgement then the message will be consumed twice. The second problem is around performance, now the broker must keep multiple states about every single message (first to lock it so it is not given out a second time, and then to mark it as permanently consumed so that it can be removed). Tricky problems must be dealt with, like what to do with messages that are sent but never acknowledged.
Kafka handles this differently. Our topic is divided into a set of totally ordered partitions, each of which is consumed by exactly one consumer within each subscribing consumer group at any given time. This means that the position of a consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
There is a side benefit of this decision. A consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but turns out to be an essential feature for many consumers. For example, if the consumer code has a bug and is discovered after some messages are consumed, the consumer can re-consume those messages once the bug is fixed.
Book
Designing Event-Driven System
Kafka:The Definitive Guide Second Edition
Kafka简介
Apache Kafka is an event streaming platform used to collect, process, store, and integrate data at scale. It has numerous use cases including distributed streaming, stream processing, data integration, and pub/sub messaging.
财富榜top100中,80%的公司用了kafka
分布式流处理,数据聚合,消息发布和订阅
Due to Kafka's high throughput, fault tolerance, resilience, and scalability, there are numerous use cases across almost every industry
高吞吐量,容错性,弹性和可扩展性
Data Integration
Metrics and Monitoring
Log Aggregation
Stream Processing
Publish-Subscribe Messaging
看到了这里:https://developer.confluent.io/what-is-apache-kafka/
kafka coordinator
"协调者"有些陌生,所谓协调者,在Kafka 中对应的术语是Coordinator,它专门为Consumer Group 服务,负责Group Rebalance 以及提供位移管理和组成员管理等。
coordinator:https://zhuanlan.zhihu.com/p/148131411
kafka整体架构:https://cloud.tencent.com/developer/beta/article/1005708?areaSource=106001.1
官方文档:https://kafka.apache.org/documentation/#consumerconfigs
Offset:https://www.cnblogs.com/edisonchou/p/kafka_study_notes_part9.html
Kafka权威指南
第一章 初识kafka
- 数据为企业发展提供动力,从数据中获取信息,对它们进行分析处理,并生成更多的数据
- 就比如:在网站上浏览了感兴趣的商品,那么浏览信息就会转化成商品推荐,展示给我们
- 如何移动数据几乎变得与数据本身一样重要,数据管道会成为关键组件
相关名词
消息
kafka的数据单元,相当于数据库中的一条“记录”,由字节数组组成
键
消息中可选的元数据,也就是键,也是字节数组,相当于数据库分区键,用来指定分区的
批次
为提高效率,消息会被分成批次写入kafka,批次包含了一组属于同一个主题和分区的消息。
模式
消息传输模式,比如常见的JSON,XML,Apache Avro—Hadoop开发的一款序列化框架
主题和分区
通过主题进行分类,好比数据库的表,可以被分成若干个分区,一个分区就是一个提交日志,消息会以追加的方式被写入分区,然后按照先入先出的顺序读取。
流
用流来描述Kafka这类系统中的数据,把一个主题的数据看成一个表,流是一组从生产者移动到消费者的数据。Kafka streams,Apache samza,Storm
生产者
消息键与分区器
消费者
消费者通过检查消息的偏移量来区分已经读过的消息,偏移量是另一种元数据
消费者组
属于同一个消费者组的一个或多个消费者共同读取一个主题,消费者与分区之间的映射通常被称为消费者对分区的所有权关系。
broker和集群
leader,follower,副本,同步,保留消息在broker
Kafka的应用场景
- 活动跟踪
- 传递消息
- 指标和日志记录
- 提交日志
- 流式计算,真正的流式处理通常是指提供了类似map/reduce(Hadoop)处理功能的应用程序。
深入Kafka
讲解思路
- Kafka 如何进⾏复制;
- Kafka 如何处理来⾃⽣产者和消费者的请求;
- Kafka 的存储细节,⽐如⽂件格式和索引。
集群成员关系
控制器broker
控制器
Kafka 使⽤ Zookeeper 的临时节点来选举控制器,并在节点加⼊集群或退出集群时通知 控制器。控制器负责在节点加⼊或离开集群时进⾏分区⾸领选举。控制器使⽤ epoch 来避免“脑 裂”。“脑裂”是指两个节点同时认为⾃⼰是当前的控制器。
控制器作用
Kafka 控制器组件(Controller) 即 Broker, 是 Kafka 的核心组件。它的主要作用是在 ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是在运行过程中,只能有一个 Broker 成为控制器,来执行管理和协调的职责。换句话说,每个正常运转的 Kafka 集群,在任意时刻都有且只有一个控制器。下面我们就来详细聊聊控制器的原理和内部运行机制。
- topic管理
- 分区重分配
- Leader选举
- 集群成员管理
- 提供数据服务
- 控制器会向其他 Broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 Broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
复制
在 Kafka 的⽂档⾥,Kafka 把⾃⼰描述成“⼀个分布式的、可分区 的、可复制的提交⽇志服务”。
⾸领副本
每个分区都有⼀个⾸领副本。为了保证⼀致性,所有⽣产者请求和消费者请求都会经过这个副 本。 跟随者副本 ⾸领以外的副本
跟随者副本
⾸领以外的副本都是跟随者副本。跟随者副本不处理来⾃客户端的请求,它们唯⼀的任务就是从 ⾸领那⾥复制消息,保持与⾸领⼀致的状态。如果⾸领发⽣崩溃,其中的⼀个跟随者会被提升为新⾸ 领。
为了与⾸领保持同步,跟随者向⾸领发送获取数据的请求,这种请求与消费者为了读取消息⽽发送的 请求是⼀样的。⾸领将响应消息发给跟随者。请求消息⾥包含了跟随者想要获取消息的偏移量,⽽且 这些偏移量总是有序的。
同步的副本
持续请求得到的最新消息副本被称为同步的副本。在⾸领发⽣失效时,只有同步副本才有可能被 选为新⾸领。
不同步副本
跟随者的正常不活跃时间或在成为不同步副本之前的时间是通过 replica.lag.time.max.ms 参数 来配置的。
元数据请求
客户端怎么知道该往哪⾥发送请求呢?客户端使⽤了另⼀种请求类型,也就是元数据请求。这种请求包含了客户端感兴趣的主题列表。服务器端的响应消息⾥指明了这些主题所包含的分区、每个分区都有哪些副本,以及哪个副本是⾸领。元数据请求可以发送给任意⼀个 broker,因为所有 broker 都缓存了这些信息。
包含⾸领副本的 broker 在收到⽣产请求时,会对请求做⼀些验证
发送数据的⽤户是否有主题写⼊权限? 请求⾥包含的 acks 值是否有效(只允许出现 0、1 或 all)? 如果 acks=all,是否有⾜够多的同步副本保证消息已经被安全写⼊?(我们可以对 broker 进 ⾏配置,如果同步副本的数量不⾜,broker 可以拒绝处理新消息。在第 6 章介绍 Kafka 持久性 和可靠性保证时,我们会讨论更多这⽅⾯的细节。)
炼狱
在消息被写⼊分区的⾸领之后,broker 开始检查 acks 配置参数——如果 acks 被设为 0 或 1,那 么 broker ⽴即返回响应;如果 acks 被设为 all,那么请求会被保存在⼀个叫作炼狱的缓冲区⾥, 直到⾸领发现所有跟随者副本都复制了消息,响应才会被返回给客户端。
零复制技术
Kafka 使⽤零复制技术向客户端发送消息——也就是说,Kafka 直接把消息从⽂件(或者更确 切地说是 Linux ⽂件系统缓存)⾥发送到⽹络通道,⽽不需要经过任何中间缓冲区。这是 Kafka 与 其他⼤部分数据库系统不⼀样的地⽅,其他数据库在将数据发送给客户端之前会先把它们保存在本地 缓存⾥。这项技术避免了字节复制,也不需要管理内存缓冲区,从⽽获得更好的性能。
Kafka 最为常⻅的⼏种请求类型
元数据请求、⽣产请求和获取请求
kafka的升级
协议在持续演化——随着客户端功能的不断增加,我们需要改进协议来满⾜需求。例如,之前的 Kafka 消费者使⽤ Zookeeper 来跟踪偏移量,在消费者启动的时候,它通过检查保存在 Zookeeper 上的偏移量就可以知道从哪⾥开始处理消息。因为各种原因,我们决定不再使⽤ Zookeeper 来保存偏移量,⽽是把偏移量保存在特定的 Kafka 主题上。
可靠性
可靠性是系统的⼀个属性,⽽不是⼀个独⽴的组件,所以在讨论 Kafka 的可靠性保证时,还是要从系统的整体出发。
有些场景要求很⾼的可靠性,⽽有些则更看重速度和简便性。
Kafka 被设计成⾼度可配置的,⽽且它的客户端 API 可以满⾜不同程度的可靠性需求。
讲解思路
- 本章先讨论各种各样的可靠性及其在 Kafka 场景中的含义。
- 然后介绍 Kafka 的复制功能,以及 它是如何提⾼系统可靠性的。
- 随后探讨如何配置 Kafka 的 broker 和主题来满⾜不同的使⽤场景需求,也会涉及⽣产者和消费者以及如何在各种可靠性场景⾥使⽤它们。
- 最后介绍如何验证系统的可靠性,因为系统的可靠性涉及⽅⽅⾯⾯——⼀些前提条件必须先得到满⾜。
可靠性保证
只有当消息被写⼊分区的所有同步副本时(但不⼀定要写⼊磁盘),它才被认为是“已提交”的。
复制
Kafka 的主题被分为多个分区,分区是基本的数据块。分区存储在单个磁盘上,Kafka 可以保证分区 ⾥的事件是有序的,分区可以在线(可⽤),也可以离线(不可⽤)。每个分区可以有多个副本,其 中⼀个副本是⾸领。所有的事件都直接发送给⾸领副本,或者直接从⾸领副本读取事件。其他副本只 需要与⾸领保持同步,并及时复制最新的事件。当⾸领副本不可⽤时,其中⼀个同步副本将成为新⾸ 领。
分区⾸领是同步副本,⽽对于跟随者副本来说,它需要满⾜以下条件才能被认为是同步的。
- 与 Zookeeper 之间有⼀个活跃的会话,也就是说,它在过去的 6s(可配置)内向 Zookeeper 发送过⼼跳。
- 在过去的 10s 内(可配置)从⾸领那⾥获取过消息。 在过去的 10s 内从⾸领那⾥获取过最新的消息。
- 光从⾸领那⾥获取消息是不够的,它还必须是⼏ 乎零延迟的。
如果跟随者副本不能满⾜以上任何⼀点,⽐如与 Zookeeper 断开连接,或者不再获取新消息,或者 获取消息滞后了 10s 以上,那么它就被认为是不同步的。
broker配置
broker 有 3 个配置参数会影响 Kafka 消息存储的可靠性。
复制系数
replication.factor,主题级别的配置参数,因为 Kafka 的默认复制系数就是 3——不过⽤户可以修改它。即使是在 主题创建之后,也可以通过新增或移除副本来改变复制系数。
如果复制系数为 N,那么在 N-1 个 broker 失效的情况下,仍然能够从主题读取数据或向主题写⼊数 据。所以,更⾼的复制系数会带来更⾼的可⽤性、可靠性和更少的故障。另⼀⽅⾯,复制系数 N 需要 ⾄少 N 个 broker,⽽且会有 N 个数据副本,也就是说它们会占⽤ N 倍的磁盘空间。我们⼀般会在 可⽤性和存储硬件之间作出权衡。
副本的分布也很重要。默认情况下,Kafka 会确保分区的每个副本被放在不同的 broker 上。
为了避免机架级别的故障,我们建议把 broker 分布在多个不同的机架上,并使⽤ broker.rack 参数来为每个 broker 配置所在机架的名字。如果 配置了机架名字,Kafka 会保证分区的副本被分布在多个机架上,从⽽获得更⾼的可⽤性。
不完全的⾸领选举
unclean.leader.election.enable只能在 broker 级别(实际上是在集群范围内)进⾏配置,它的默认 值是 true。
我们之前提到过,当分区⾸领不可⽤时,⼀个同步副本会被选为新⾸领。如果在选举过程中没有丢失 数据,也就是说提交的数据同时存在于所有的同步副本上,那么这个选举就是“完全”的。 但如果在⾸领不可⽤时其他副本都是不同步的,我们该怎么办呢?
简⽽⾔之,如果我们允许不同步的副本成为⾸领,那么就要承担丢失数据和出现数据不⼀致的⻛险。 如果不允许它们成为⾸领,那么就要接受较低的可⽤性,因为我们必须等待原先的⾸领恢复到可⽤状 态。
如果把 unclean.leader.election.enable 设为 true,就是允许不同步的副本成为⾸领(也就 是“不完全的选举”),那么我们将⾯临丢失消息的⻛险。如果把这个参数设为 false,就要等待原先 的⾸领重新上线,从⽽降低了可⽤性。
银行系统,信用卡支付事务/实时点击流分析系统
最少同步副本
在主题级别和 broker 级别上,这个参数都叫 min.insync.replicas。
根据 Kafka 对可 靠性保证的定义,消息只有在被写⼊到所有同步副本之后才被认为是已提交的。
对于 ⼀个包含 3 个副本的主题,如果 min.insync.replicas 被设为 2,那么⾄少要存在两个同步副本 才能向分区写⼊数据。 如果 3 个副本都是同步的,或者其中⼀个副本变为不可⽤,都不会有什么问题。不过,如果有两个副 本变为不可⽤,那么 broker 就会停⽌接受⽣产者的请求。尝试发送数据的⽣产者会收到 NotEnoughReplicasException 异常。消费者仍然可以继续读取已有的数据。实际上,如果使⽤ 这样的配置,那么当只剩下⼀个同步副本时,它就变成只读了,这是为了避免在发⽣不完全选举时数 据的写⼊和读取出现⾮预期的⾏为。为了从只读状态中恢复,必须让两个不可⽤分区中的⼀个重新变 为可⽤的(⽐如重启 broker),并等待它变为同步的
在可靠的系统⾥使⽤⽣产者
- 根据可靠性需求配置恰当的 acks 值。
- 在参数配置和代码⾥正确处理错误。
acks(0,1,all)
⼀般情况下,如果你的⽬标是不丢失任何消息,那么最好让⽣产者在遇到可重试错误时能够保持重 试。
重试发送⼀个已经失败的消息会带来⼀些⻛险,如果两个消息都写⼊成功,会导致消息重 复。重试和恰当的错误处理可以保证每个消息“⾄少被保存⼀次”,但当前 的 Kafka 版本(0.10.0)⽆法保证每个消息“只被保存⼀次”。
在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture)或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
所谓的消息交付可靠性保障,是指 Kafka 对 Producer 和 Consumer 要处理的消息提供什么样的承诺。常见的承诺有以下三种:
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
使⽤⽣产者内置的重试机制可以在不造成消息丢失的情况下轻松地处理⼤部分错误,不过对于开发⼈ 员来说,仍然需要处理其他类型的错误,包括:
- 不可重试的 broker 错误,例如消息⼤⼩错误、认证错误等;
- 在消息发送之前发⽣的错误,例如序列化错误;
- 在⽣产者达到重试次数上限时或者在消息占⽤的内存达到上限时发⽣的错误
- 丢弃“不合法的消息”?
- 把错误记录下来?
- 把这些消息保存在本地 磁盘上?
- 回调另⼀个应⽤程序?
具体使⽤哪⼀种逻辑要根据具体的架构来决定。只要记住,如果错误处理只是为了重试发送消息,那么最好还是使⽤⽣产者内置的重试机制。
在可靠的系统⾥使⽤消费者
消费者的可靠性配置
- group.id
- auto.offset.reset
- enable.auto.commit
- auto.commit.interval.ms
精准一次、幂等性写⼊
总结
正如我们在本章开头所说的,可靠性并不只是 Kafka 单⽅⾯的事情。我们应该从整个系统层⾯来考虑 可靠性问题,包括应⽤程序的架构、⽣产者和消费者 API 的使⽤⽅式、⽣产者和消费者的配置、主题 的配置以及 broker 的配置。系统的可靠性需要在许多⽅⾯作出权衡,⽐如复杂性、性能、可⽤性和 磁盘空间的使⽤。掌握 Kafka 的各种配置和常⽤模式,对使⽤场景的需求做到⼼中有数,你就可以在 应⽤程序和 Kafka 的可靠性程度以及各种权衡之间作出更好的选择。
Asks=-1,会导致程序阻塞,
讲解思路
- AKF
- 可靠性保证
- kafka的使用场景
ChatGPT写的一篇《Kafka权威指南》总结
《Kafka权威指南》是一本介绍Apache Kafka的技术书籍,是Kafka领域的经典著作之一。在这篇技术分享中,我将从以下几个方面介绍Kafka的核心概念和应用场景。
1. Kafka的基本概念
Kafka是一个分布式流处理平台,主要用于实时处理大规模数据流。在Kafka中,数据被组织成一个或多个主题(Topic),每个主题包含一个或多个分区(Partition),每个分区又由多个消息(Message)组成。生产者(Producer)将消息发送到指定的主题中,而消费者(Consumer)则从指定的主题中读取消息。此外,Kafka还提供了一个可靠的消息传输机制,确保消息在发送和接收过程中不会丢失或重复。
2. Kafka的应用场景
Kafka的应用场景非常广泛,特别适合以下几个方面:
- 实时数据采集和处理:Kafka可以作为数据采集和处理的中间件,用于收集和处理来自各种数据源的实时数据流,例如日志数据、传感器数据、网络数据等。
- 大规模数据处理:Kafka可以作为数据集成和分发的中间件,用于支持大规模数据处理和分析,例如批处理、流处理、机器学习等。
- 消息队列:Kafka可以作为高吞吐量、低延迟的消息队列,用于处理大量的实时消息,例如在线交易、聊天应用、游戏等。
3. Kafka的优势和挑战
Kafka具有以下几个优势:
- 高吞吐量:Kafka能够支持每秒数百万条消息的高吞吐量,适用于大规模数据处理和实时数据流处理场景。
- 可扩展性:Kafka可以通过添加新的节点来扩展性能和容量,支持水平扩展和垂直扩展。
- 可靠性:Kafka提供了可靠的消息传输机制,确保消息不会丢失或重复,支持多副本备份和故障转移。
- 灵活性:Kafka的消息存储和处理机制非常灵活,可以灵活配置主题、分区和消费者组等参数。
然而,Kafka也面临一些挑战:
- 复杂性:Kafka的配置和管理比较复杂,需要投入大量的人力和物力来维护和管理。
- 学习成本:Kafka的核心概念和工作原理比较复杂,需要花费一定的时间和精力来学习和理解。
- 系统稳定性:Kafka的稳定性和可靠性受到很多因素的影响,例如网络延迟、磁盘故障、节点故障等。
4. Kafka的应用实践
Kafka在实际应用中有很多应用场景和应用实践,例如:
- 数据集成和分发:使用Kafka将各种数据源集成到一个统一的数据平台中,支持批量处理和实时处理等多种数据处理方式。
- 实时日志处理:使用Kafka作为日志的收集和分发平台,支持日志的实时处理和分析,例如日志监控、异常检测等。
- 流处理:使用Kafka作为流处理平台,实现实时数据流的处理和分析,例如实时计算、实时推荐、实时预测等。
- 消息队列:使用Kafka作为高吞吐量、低延迟的消息队列,支持在线交易、聊天应用、游戏等高并发场景。
除此之外,Kafka还可以和其他大数据技术结合使用,例如和Hadoop、Spark、Flink等进行数据集成和分析,形成一个完整的大数据处理和分析体系。
5. 从哪些方面入手Kafka
为了更好地应用Kafka,建议从以下几个方面入手:
- 学习Kafka的核心概念和工作原理,理解Kafka的消息传输机制、主题、分区、生产者、消费者等重要概念。
- 熟悉Kafka的应用场景和应用实践,了解Kafka在实际应用中的优势和挑战,以及如何将Kafka应用于不同的场景。
- 掌握Kafka的配置和管理技巧,了解如何优化Kafka的性能和稳定性,如何配置Kafka的主题、分区、消费者组等参数。
- 学习Kafka的客户端API和工具,掌握如何使用Kafka的生产者API、消费者API、管理工具等,进行数据传输、数据处理和数据管理。
- 掌握Kafka的监控和调试技巧,了解如何监控Kafka的运行状态、诊断Kafka的故障、调优Kafka的性能等。
总之,Kafka是一款非常强大的分布式流处理平台,具有广泛的应用场景和应用实践,但是也需要投入大量的人力和物力来维护和管理。通过深入学习和实践Kafka,可以更好地应用Kafka,实现大规模数据处理和实时数据流处理的需求。
6. 常见的问题和解决方案
另外,值得注意的是,Kafka在实际应用中也存在一些常见的问题和挑战,例如:
- 消费者组的负载均衡问题:Kafka的消费者组需要进行负载均衡,确保每个消费者处理相同数量的消息,避免出现负载不均衡的情况。
- 消费者的偏移量管理问题:Kafka的消费者需要管理自己的偏移量,避免出现重复消费或漏消费的情况。
- 消息丢失和重复问题:尽管Kafka提供了可靠的消息传输机制,但是在实际应用中仍然可能出现消息丢失或重复的情况。
针对这些问题,可以采取一些措施来解决,例如:
- 使用消费者组协调器来实现消费者组的负载均衡,确保每个消费者处理相同数量的消息。
- 使用Kafka的偏移量管理机制,确保每个消费者能够正确地管理自己的偏移量,避免出现重复消费或漏消费的情况。
- 配置Kafka的消息保留策略和副本数,确保消息不会丢失或重复。
最后,需要注意的是,Kafka的应用需要结合具体的业务场景和需求来考虑,需要根据实际情况进行配置和调优,才能发挥Kafka的最佳性能和效果。
7. Kafka的生态系统
除此之外,Kafka的生态系统也非常丰富,有很多与Kafka相关的工具和技术,例如:
- Kafka Connect:Kafka Connect是一款开源的数据集成工具,可以将Kafka与其他数据源和数据目的地进行集成,支持多种数据格式和协议。
- Kafka Streams:Kafka Streams是一款开源的流处理框架,可以对Kafka中的数据进行实时处理和分析,支持多种数据操作和聚合操作。
- Confluent Platform:Confluent Platform是一款基于Kafka的企业级数据中心,提供了一系列与Kafka相关的工具和服务,例如Schema Registry、Kafka REST Proxy、Control Center等。
- Apache NiFi:Apache NiFi是一款开源的数据流处理工具,可以将Kafka与其他数据源和数据目的地进行集成,支持多种数据格式和协议。
- Apache Beam:Apache Beam是一款开源的分布式数据处理框架,可以对Kafka中的数据进行批处理和流处理,支持多种数据操作和聚合操作。
这些工具和技术可以帮助用户更好地应用Kafka,实现更多的数据处理和分析需求。同时,也需要注意选择合适的工具和技术,根据实际场景和需求进行选择和配置,才能实现最佳的性能和效果。
8. 总结
作为一款分布式流处理平台,Kafka具有高吞吐量、可扩展性、可靠性和灵活性等特点,适用于大规模数据处理和实时数据流处理场景。同时,Kafka也面临着复杂性、学习成本和系统稳定性等挑战,需要投入大量的人力和物力来维护和管理。在实际应用中,Kafka可以应用于数据集成和分发、实时日志处理、流处理和消息队列等多种场景,并且可以和其他大数据技术结合使用,形成一个完整的大数据处理和分析体系。
Apache Kafka实战
深入理解Kafka
Apache Kafka源码剖析
Kafka简介
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Confluent: Set Your Data in Motion
Confluent is creating the foundational platform for data-in-motion
提供的新架构,解决方案
事件流处理平台
事件处理
上次学到这里
Event Streaming Patterns:https://developer.confluent.io/patterns/event/event/
inside-ksqldb:https://developer.confluent.io/learn-kafka/inside-ksqldb/streaming-architecture/
笔记
Kafka
Kafka是事件处理平台,提供了事件存储能力Kafka的Log,事件计算KSQLDB,Kafka Stream。
Kafka Ecosystem: Kafka,Kafka Stream,Kafka Connect,KSQLDB.
事件处理中出现了问题,那么Materialize可以是发邮件,也可以是存到存储系统中。
kafka发送消息是k,v类型的。没发送一个消息,offset+1 m https://developer.confluent.io/learn-kafka/event-sourcing/event-driven-vs-state-based/
软件设计方法:
state-based(databases+ synchronous network call)
event-based(data at rest + data in motion + event sourcing + CQRS + event streaming)
CRUD:Databases
CR:Event Sourcing
Topic:Event:Key:Partition,Schema
Table:Row:Primary Key,Shard,Schema
Index:Document:_id,Shard,Mapping
Collection:Document:DocumentId,Shard,Schema
Kafka Queue is Log:Append Only and Durable,Reading Message never delete. Other Message is Queue. Message is Bounded Buffer can be deleted. Topic is Log. Not Queue. Topic(DLT) is Queue(DLQ).
same key -> same partition -> in order ,key is null -> round robin ,key is nonull -> hash function
rewind,reprocess,replayable,reblance,
consumer group protocol(join+leave)
Kafka Connector
Consumer+Materialize = Kafka Connect ,Consumer+Stateful = Kafka Stream ,Consumer+Stateless = Kafka Consumer
数据是流动的处理平台(Kafka)和数据是静止的处理平台(MySQL)
DLQ:Dead Letter Queue
Kafka Stream
KTable:Last Updated Value
Kafka Core: Log+Event
Kafka Stream = KStream,KTable,Serialization,Joins,Stateful Operations,Windowing,Times,Processor,
Joins:Stream-Stream(Windows),Stream-Table,Table-Table
Stateless:filter,map, Stateful(use pre event):group by key,reduce,aggregation(sum,count,avg,max,min),join
Time Windows: https://kafka.apache.org/30/javadoc/org/apache/kafka/streams/kstream/TimeWindows.html
Session Windows: https://kafka.apache.org/30/javadoc/org/apache/kafka/streams/kstream/SessionWindows.html
SlidingWindows: https://kafka.apache.org/30/javadoc/org/apache/kafka/streams/kstream/SlidingWindows.html
ksqlDB
ksqlDB:distributed compute layer kafka:distributed storage layer
Streams:unbounded series of event. Table: the current state of event
Stateful Aggregations (Materialized Views)
ksqlDB can build a materialized view of state
Kafka is a database turned inside out
Data Mesh
software architecture vs data architecture
service mesh vs data mesh
配置
broker配置
default.replication.factor
unclean.leader.election.enable
min.insync.replicas
producer配置
acks(0,1,all)
设计
https://docs.confluent.io/platform/current/kafka/design.html
实现
FAQ
https://developer.confluent.io/learn/apache-kafka-faqs/
其他
The Streams API in Kafka and Flink are used in both capacities. The main distinction lies in where these applications live — as jobs in a central cluster (Flink), or inside microservices (Streams API).
The Streams API makes stream processing accessible as an application programming model, that applications built as microservices can avail from, and benefits from Kafka’s core competency —performance, scalability, security, reliability and soon, end-to-end exactly-once — due to its tight integration with core abstractions in Kafka. Flink, on the other hand, is a great fit for applications that are deployed in existing clusters and benefit from throughput, latency, event time semantics, savepoints and operational features, exactly-once guarantees for application state, end-to-end exactly-once guarantees (except when used with Kafka as a sink today), and batch processing.
疑问
kafka一个topic多个消费组情况下,broker是怎么管理log的offset的呢,是每一个消费组提交自己的呢,还是共同提交?
Operations
消费者操作
打印指定偏移量的消费者的消息
./kafka-console-consumer.sh --bootstrap-server brokerIP:brokerPort --topic yourTopic --partition 0 --offset 19831988 --property print.key=true --max-messages 1
其他属性有: print.timestamp Set to true to display the timestamp of each message (if available). print.key Set to true to display the message key in addition to the value. print.offset Set to true to display the message offset in addition to the value. print.partition Set to true to display the topic partition a message is consumed from. key.separator Specify the delimiter character to use between the message key and message value when printing. line.separator Specify the delimiter character to use between messages. key.deserializer Provide a class name that is used to deserialize the message key before printing. value.deserializer Provide a class name that is used to deserialize the message value before printing.
消费组操作
查看消费组
./kafka-consumer-groups.sh --bootstrap-server brokerIP:brokerPort --describe --group yourGroup
重置消费者偏移量
./kafka-consumer-groups.sh --bootstrap-server brokerIP:brokerPort --group yourGroup --topic yourTopic --reset-offsets --to-offset yourOffset --execute
./kafka-consumer-groups.sh --bootstrap-server brokerIP:brokerPort --group yourGroup --topic yourTopic --reset-offsets -to-latest --execute
Streaming
book:making sense of stream processing
Data Integration Problem: Log VS Dual Write
The database is a cache of a subset of the log.
表:更新流,对事实的更新 流:事件流,无界事件
Akka
lightbend-academy
reactive programming vs reactive system vs reactive architecture
Reactive Programming doesn't mean you have created a Reactive System
Reactive System: Reactive Microservice
A system that uses Reactive Programming is not necessarily Reactive.
Location Transport VS Transport Remoting
Reactive Architecture:DDD,Lagom
Reactive Architecture + DDD = same goal
Many of the guidelines and rules in Domain Driven Design are compatible with those in Reactive Architecture.
Akka简介
Build powerful reactive, concurrent, and distributed applications more easily
Akka is a toolkit for building highly concurrent, distributed, and resilient message-driven applications for Java and Scala.
提供的新架构,解决方案
反应式架构,反应式系统,反应式编程
Reactive Systems Architecture
Reactive Architecture:LightBend
The primary goal of reactive architecture is to provide an experience that is responsive under all conditions.
unresponsive software
Lightbend=Akka+Play+Lagom
akka监控:https://www.lightbend.com/blog/akka-monitoring-telemetry
其他
Lightbend CEO Jonas Boner-blog
Jonas Boner's Book: Reactive Microservices Architecture Reactive Microsystems The Reactive Principles - Design Principles for Distributed Applications
foreword—reactive Messaging Patterns with the Actor Model - 《响应式架构》 foreword—reactive application development - 《反应式应用开发》 foreword—reactive design patterns - 《反应式设计模型》 foreword—functional and reactive domain modeling - 《函数响应式领域建模》
Readlist: http://jonasboner.com/books-that-makes-you-think/
My Repo
https://github.com/xiaozhiliaoo/akka-in-action.git
https://github.com/xiaozhiliaoo/akka-practice
https://github.com/xiaozhiliaoo/learning-akka.git
https://github.com/SalmaKhater/Learning-Akka
使用场景
可扩展的分布式内存数据库
Akka Actor
Progress
Notes
tell,do not ask!
发消息方法: tell(fire and forget) ask(get response) pub/sub
acotr单线程模型,并发安全
become 通过行为改变状态
当actor中出现futrue时候,可以使用pipeline,否则会打破单线程模式
akka,riak,cassandra
ActorRef,ActorPath,Actor Selection
Replace Actor stack behavior vid become/unbecome/FSM
Actor如果是计数器,那么需要持久化。Stateful Actor
Sender -> Command -> Actor -> Event -> DB
线上推荐akka cluster,而不是remote
Send messages:Tell:fire-forget,Ask:Send-And-Receive-Future
Forward message: useful when writing actors that work as routers, load-balancers, replicators etc.
Reference
https://doc.akka.io/docs/akka/current/actors.html#actor-lifecycle
Akka Remoting
Classic Remoting (Deprecated) -> Typed Artery Remoting
https://doc.akka.io/docs/akka/current/remoting.html
akka通信协议,序列化机制是什么?
Akka Http
akka-http收http://spray.io/启发
Akka http = Akka + Akka stream
Akka TestKit
Akka Stream
Akka Distributed Data
多点写入冲突解决: 具有中央节点的数据修改,也涉及CRDT,因为时间有先后,但是最终选哪一个也是问题。多节点更新,然后节点同步达到一致性时候,会有冲突。
除非所有写入本身就存储在一个中央节点,
akka生态至少把akka项目看完,lightbend生态
core
convergent(收敛)
集群中节点间复制简单的会话信息。ORSet Observer Remove Set
Related
https://github.com/lmdbjava/lmdbjava/wiki
paper: Delta State Replicated Data Types
Akka Cluster
学习进度
https://doc.akka.io/docs/akka/current/typed/cluster.html#
笔记
application membership(heartbeat, gossip)
CAP:
available(pick up consistency):membership,distributed data,pubsub,multi-dc support consistency:singleton,sharding,leases
stateful applications
集群单例生成唯一用户ID
Akka Persistent + Akka Singleton 生成唯一用户ID
计算集群总请求数。
发现资源不够,会自动扩展actor来处理任务,资源充足,会减少actor来处理任务
全局状态:集群单例actor实现
actor中有阻塞操作该怎么办?
如果一个分片挂了,那么akka cluster shard是如何处理任务的?
集群路由感知器比集群单例更通用的构造。一个actor可以将任务推给多个worker.
Classic Cluster Aware Router:https://doc.akka.io/docs/akka/current/cluster-routing.html
Akka Persistence
Classic Persistence:https://doc.akka.io/docs/akka/current/persistence.html#at-least-once-delivery
Notes
https://github.com/dnemov/akka-persistence-jdbc/blob/master/src/main/resources/schema/mysql/mysql-schema.sql
Akka Utilities
熔断器
https://doc.akka.io/docs/akka/current/common/circuitbreaker.html
let it crash. 从奔溃中恢复才是弹性系统应该具备的能力。
Book
Akka实战
Akka入门与实践
Akka应用模式
反应式设计模式
反应式应用开发
Progress
Notes
Akka的actor模型中,并没有提供因果一致性,因此落在了开发人员,需要通过Process Manager模式完成Become/Unbecome实现因果一致性。
反应式架构默认是分布式的。
Akka分片:跨集群中多个节点自动分布具有标识符的actor.
Question
消息,命令,事件区别?
Hazelcast
Consul简介
Consul is a service mesh solution providing a full featured control plane with service discovery, configuration, and segmentation functionality.
Hashicorp:delivers consistent workflows to provision, secure, connect, and run any infrastructure for any application.
提供的新架构,解决方案
FAQ
线上容器里面是怎么连上的consul?
consul使用模式?线上部署模式?教务总共三个node,service全部在node上,其他电商的node就是service.
service -> consul client(3 pod) -> consul server()
Consul Agent,Server,Client,Consul cluster,
Using Lib
https://github.com/Ecwid/consul-api
Paper
-
SWIM:Scalable Weakly-consistent Infection-style Process Group Membership Protocol
-
Lifeguard:Local Health Awareness for More Accurate Failure Detection
Wiki
Hazelcast
Hazelcast简介
Hazelcast is a streaming and memory-first application platform for fast, stateful, data-intensive workloads on-premises, at the edge or as a fully managed cloud service.
产品有:Hazelcast Management Center,IMDG,Jet
学习进度
提供的新架构,解决方案
笔记
HZ核心设计文档:https://github.com/hazelcast/hazelcast/blob/master/docs/design/template.md
Bridging Between Java 8 Streams and Hazelcast Jet
In-Memory Storage/In-Memory Compute/Real-Time Processing
Distributed Data Design(Partitioning and Replication): AP:Replication(lazy replication), primary-copy, best-effort, no strong consistency but monotonic reads guarantee, anti-entropy,at-least-once, CP: Consensus algorithms Raft
嵌入式是否支持”跨应用”发现彼此?
membership具体细节,如何加入和如何退出,以及数据迁移细节官方文档涉及比较少。
Build Distributed System
Core Object:Config,DistributedObject,Node,NodeState,Cluster,HazelcastInstance
FD:PhiAccrualFailureDetector,PhiAccrualClusterFailureDetector,DeadlineClusterFailureDetector,PingFailureDetector
Starter
https://docs.hazelcast.com/hazelcast/5.1/pipelines/spring-boot
Paper
cluster
Discovery Mechanisms
Auto Detection:multicast TCP/IP Cloud Discovery
Distributed Data Structures
数据结构选择依据:1 是否partitioned 2 AP or CP保证
AP:
Jackson
Jackson简介
ElasticStack
ElasticSearch
学习进度
看到这里了:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_preventing_combinatorial_explosions.html
笔记
Near Real Time
打分机制:从TF-IDF改成BM25,也叫similarity ,scoring,ranking
oversharding问题,如何创建分片数?
如何知道数据在集群中的哪个节点?
es和mysql数据模型区别?
结构化搜索和全文搜索
全文搜索:传统数据库确实很难搞定的任务,传统数据库要么匹配,要么不匹配,es有相关性打分。
PB级别,数百台服务器
一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎
每个字段的所有数据都是默认被索引的
index是逻辑概念,面向用户,shard是物理概念,面向机器,应用程序关心索引,而不是分片
Elasticsearch中文档是不可改变的,不能修改它们,在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档,并且会重新进行索引。
更新文档:标记删除,创建文档,重新索引,检索-修改-重建索引
文档中的每个字段都将被索引并且可以被查询
在分布式系统中深度分页:在分布式系统中,对结果排序的成本随分页的深度成指数上升
filed:精确值,全文值
很少对全文类型的域做精确匹配
Doc Values:排序,聚合,脚本计算 Invert Index:检索
文档的唯一性:index,type,routing value
检索过程:query then fetch 先查后取 分片节点:from+size 协调节点:numberOfShard * (from+size)
scroll 查询禁用排序
搜索类型:query then fetch,dfs_query_then_fetch
深度分页的代价根源是结果集全局排序,如果去掉全局排序的特性的话查询结果的成本就会很低。
Data Replication:Primary-Backup
in-sync shard(可以被选中为primary的shard)
index配置最重要的是:number_of_shards(创建后更改不了),number_of_replicas(创建后可以修改)
_id 和 _index 字段则既没有被索引也没有被存储,这意味着它们并不是真实存在的。
不能添加新的分析器或者对现有的字段做改动。 如果你那么做的话,结果就是那些已经被索引的数据就不正确, 搜索也不能正常工作。reindex
修改索引类型:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-aliases.html
应用中使用索引别名,而不是索引真实名字。这样在修改索引时候,应用层不需要变化。
全文检索=全字段索引
倒排索引被写入磁盘后是 不可改变 的 在保留不变性的前提下实现倒排索引的更新?答案是: 用更多的索引。
一个 Lucene 索引包含一个提交点和三个段
一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个 Elasticsearch 索引 是分片的集合
段是不可改变的
内存索引缓冲区
按段搜索
写入和打开一个新段的轻量的过程叫做 refresh,每1s refresh下
Elasticsearch是近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见
Flush:执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush,30分钟一次。 Flush之后段被全量提交,并且事务日志被清空
减少段的数量(通常减少到一个),来提升搜索性能。
结构化搜索:要么在,要么不在,和打分机制无关系。也就是和相似度无关。
精确值查找时候,需要用filter,不会被打分,会被缓存。
尽可能多的使用过滤式查询。
constant_score(常量评分查询) 将 term 查询转化成为过滤器。
term查询转成constant_score查询。(非评分查询)
非评分计算是首先执行的,这将有助于写出高效又快速的搜索请求。
bool过滤器,也叫复合过滤器。
查看索引别名:GET /finance_netease_settle_order/_alias
布尔过滤器可以用来作为构造复杂逻辑条件的基本构建模块。
term 和 terms 是 包含(contains) 操作,而非 等值(equals)
查询优化:普通查询 -> bool filter -> constant_score filter
exists(!=null),missing(==null)查询
filter query 实现bitset的roraing bitmap
bool match查询
多数字符串字段都是 not_analyzed 精确值字段
dfs_query_then_fetch: dfs是指分布式频率搜索(Distributed Frequency Search) , 它告诉 Elasticsearch , 先分别获得每个分片本地的 IDF ,然后根据结果再计算整个索引的全局 IDF 。
多字段搜索:bool match查询
dis_max:分离最大化查询(Disjunction Max Query)
全文搜索被称作是 召回率(Recall) 与 精确率(Precision) 的战场 召回率 ——返回所有的相关文档; 精确率 ——不返回无关文档
TF/IDF
字段中心式(term-centric)查询:best_fields 和 most_fields 词中心式(term-centric)的查询:cross_fields
自定义单字段查询是否能够优于多字段查询,取决于在多字段查询与单字段自定义 _all 之间代价的权衡, 即哪种解决方案会带来更大的性能优化就选择哪一种。
multi_match 查询中避免使用 not_analyzed 字段。
短语匹配(match_phrase查询)
http://people.apache.org/~mikemccand/lucenebench/
unigrams ,bigrams(shingles),trigrams,
shingles 不仅比短语查询更灵活,而且性能也更好。 shingles 查询跟一个简单的 match 查询一样高效,而不用每次搜索花费短语查询的代价。
prefix 查询不做相关度评分计算,它只是将所有匹配的文档返回,并为每条结果赋予评分值 1 。它的行为更像是过滤器而不是查询。
search-as-you-type:match_phrase_prefix
Boolean Model:只是在查询中使用 AND 、 OR 和 NOT
Lucene 使用 布尔模型(Boolean model) 、 TF/IDF 以及 向量空间模型(vector space model) ,然后将它们组合到单个高效的包里以收集匹配文档并进行评分计算。
bool 查询实现了布尔模型
查询时的权重提升 是可以用来影响相关度的主要工具
constant_score 和 function_score区别?
一致随机评分(consistently random scoring)
similarity算法:BM25,TF-IDF
全文搜索是一场 查准率 与 查全率 之间的较量—查准率即尽量返回较少的无关文档,而查全率则尽量返回较多的相关文档。
es多字段,可对字段建立两次索引。文本做两次索引
stem 词干 stemmer 词干提取器
多语言设计:index-per-language, field-per-language
Elasticsearch 为什么不能在 analyzed (分析过)的字符串字段上排序,并演示了如何为同一个域创建 复数域索引 , 其中analyzed域用来搜索,not_analyzed域用来排序。
Analyzed 域无法排序并不是因为使用了分析器,而是因为分析器将字符串拆分成了很多词汇单元,就像一个 词汇袋 , 所以 Elasticsearch 不知道使用那一个词汇单元排序。
analyzed name域用来搜索。 not_analyzed name.raw 域用来排序。
International Components for Unicode (ICU)
单词还原成词根。比如foxes还原成fox.
Internals
https://www.elastic.co/blog/found-elasticsearch-internals https://www.elastic.co/blog/found-elasticsearch-networking
遇到问题
1.forbidden-12-index-read-only-allow-delete-api?
某个节点的磁盘满了,需要运维清理下磁盘
Course
https://github.com/xiaozhiliaoo/geektime-ELK
https://github.com/xiaozhiliaoo/search-practice
LogStash
笔记
kibana
笔记
beat
reference
https://www.elastic.co/guide/en/beats/libbeat/8.0/beats-reference.html
Lucene
Book
Elasticsearch权威指南
Progress
100%
Notes
Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine 1st Edition
TF-IDF:词频/逆向文档频率
es两个阶段:索引和查询
stemmer:词干提取器
synonyms:同义词
字典词干提取器,算法化词干提取器
实践中一个好的算法化词干提取器一般优于一个字典词干提取器。
Hunspell 词干提取器(拼写检查)
保留停用词最大的缺点就影响搜索性能。
索引结构:Terms dictionary,Postings list,Term frequency,Positions,Offsets,Norms
common_grams 过滤器是针对短语查询能更高效的使用停用词而设计的。
Fuzzy matching 允许查询时匹配错误拼写的单词。原理是编辑距离
fuzzy 查询的工作原理是给定原始词项及构造一个 编辑自动机— 像表示所有原始字符串指定编辑距离的字符串的一个大图表。
聚合=bucket+metrics bucket=group by metrics=count,sum,max...
<国家, 性别, 年龄> 组合的平均薪酬。所有的这些都在一个请求内完成并且只遍历一次数据.
直方图聚合:histogram,date_histogram
例子基础数据 POST /cars/transactions/_bulk { "index": {}} { "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" } { "index": {}} { "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" } { "index": {}} { "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
聚合是在查询范围内的,但有时我们也想要搜索它的子集,而聚合的对象却是所有数据:全局桶
聚合结果过滤:过滤桶
只过滤搜索结果,不过滤聚合结果:post_filter
Approximate Aggregations(近似聚合):cardinality(HyperLogLog),percentiles(TDigest-https://github.com/tdunning/t-digest)
max是精确聚合,count(DISTINCT)是近似聚合
big data, exactness, and real-time latency.
精确+实时:数据可以存入单台机器的内存之中,我们可以随心所欲,使用任何想用的算法。结果会 100% 精确,响应会相对快速。 大数据+精确:传统的 Hadoop。可以处理 PB 级的数据并且为我们提供精确的答案,但它可能需要几周的时间才能为我们提供这个答案。 大数据+实时:近似算法为我们提供准确但不精确的结果。
聚合实现:DocValues
Doc values 的存在是因为倒排索引只对某些操作是高效的。 倒排索引的优势在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里 搜索使用倒排索引查找文档,聚合操作收集和聚合 doc values 里的数据。 Doc Values 本质上是一个序列化的列式存储。列式存储 适用于聚合、排序、脚本等操作 Doc values 不支持 analyzed 字符串字段。聚合运行在 not_analyzed 字符串而不是 analyzed 字符串,这样可以有效的利用 doc values
聚合一个分析字符串:fielddata
terms 桶基于我们的数据动态构建桶;它并不知道到底生成了多少桶。 大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多个字段时,就可能会 产生大量的分组,最终结果就是占用 es 大量内存,从而导致 OOM 的情况发生。
聚合模式:DFS(默认),BFS
广度优先仅仅适用于每个组的聚合数量远远小于当前总组数的情况下,因为广度优先会在内存中缓存裁剪后的仅仅需要缓存的每个组的所有数据, 以便于它的子聚合分组查询可以复用上级聚合的数据。
对单个文件的变更是ACID的,但包含多个文档的变更不支持。
Elasticsearch实战
Progress
P47
深入理解Elasticsearch(原书第三版)
进度
阅读完成
Notes
prefix-query不会被分析,match query会被分析
es1.0多播发现机制,2.0单播默认发现机制。zen discovery
ingest等价于java版logstash节点
shrink api 索引收缩
查询数据:查询,过滤器
normalization 归一化
BM25和TF-IDF
es当作NOSQL,无分析查询会更好。也即精确查询。
基本查询:match,multi_match,common,fuzzy_like_this,fuzzy_like_this_field,geoshape,ids,match_all,query_string,simple_query_string range,prefix,regex,span_term,term,terms,wildcard
组合查询:bool,boosting,constant_score,dis_max,filtered,function_score,has_child,has_parent,indices,nested,span_first,span_multi, span_near,span_not,span_or,span_term,top_children
无分析查询:term,terms,common,ids,prefix,span_term,wildcard
全文检索:match,multi_match,query_string,simple_query_string
模式匹配:prefix,regexp,wildcard
相似度查询: fuzzy,fuzzy_like_this,fuzzy_like_this_filed,more_like_this,more_like_this_field
支持修改分数查询:boosting,constant_score,function_score,indices
位置敏感:match_pjrase,span_first,span_multi,span_near,span_not,span_or,span_term
结构敏感:nested,has_child,has_parent,top_children
查询改写:prefix,rewrite参数
es使用mustache实现查询模板
multi_match匹配类型:best_fields,most_fields,cross_fields,phrase,phrase_prefix
es管理关系型提供了:嵌套,父子文档结构
处理人类语言。
文档通过路由知道放在哪一个分片上面了。
集群主节点任务:节点间分配分片。
分片是一个lucence索引。
相似度模型(similarity):TF-IDF,BM25,DFR,DFI,IB,LM Dirichlet,LM JelinekMercer
store模块:lucene和io子系统的抽象:niofs,simplefs,mmapfs,fs
Searcher重新打开的过程:refresh,默认1s
flush:将事务日志同步到lucene index,同时清空事务日志。默认5s
实时读取:从事务日志中读取。
段合并耗费性能的操作。
并发合并调度器:ConcurrentMergeScheduler
NRT:近实时
发现模块:选主,发现新节点,形成和发现新节点过程叫发现。 Zen发现模块单播(unicast)发现集群中其他节点。
微服务发现是发现别人,但是自己发现不了。
es恢复过程:加载通过网关模块存储的数据以使得es正常工作。每当集群整体启动时候,恢复过程就会启动,加载所有数据:元数据,映射和全部索引。 网关模块存储es正常运行的全部数据。
es可以备份到s3,hdfs,gcs,azure
ingest处理器,内置23个等。append,convert,grok,fail等等。。。grok自带了120多种grok模式。
联盟搜索:跨集群搜索,通过部落节点
部落节点从所有连接的集群中获取集群状态,合并成一个集群状态。
percolation(过滤),suggester(联想,建议器)
查询验证 validate api
查询分析器:profile api
dfs query then fetch
发现集群变慢,阻塞等情况时候,可以看到热点线程api,看哪些线程耗费cpu,io等信息 hot_threads
当数据量够大,查询够复杂时候,就会碰到内存问题,此时增加更多内存也无济于事。
增加主分片:内存溢出,分片查询时间过长,内存交换,高IO等待等问题 增加副本分片:流量过高节点无法处理的时候,增加查询能力。
集群缺少部分节点数据,比完全不响应查询要好。
防止分片和副本部署在同一个节点,此时失去了高可用能力了。使用awareness能力。
集群部署:两个聚合节点,n个数据节点,三个候选主节点,冗余3个。设置minimum_master_nodes:2,可以避免脑裂发生。
索引刷新频率:文档需要多久才能出现在搜索结果里面。默认1s,意味着每1s索引查询器重新打开一次。
查询:总应该思考最优的查询结构,过滤器使用等。
不使用路由情况下,es会查询所有分片。如果知道文档在哪一个路由里面,将会提高效率。
索引只在一个分片上面,查询性能较差,增加副本分片对性能提高无用,需要将索引分为多个分片。把数据平均负载。
聚合查询:size:最后聚合结果返回多少组数据,shard_size:每个分片返回多少组数据。 降低size和shard_size会让聚合结果不那么准确,但是网络开销小,内存使用低。
过多的副本会导致索引速度下降。
es 预写日志WAL,tranlog,get请求获取最新的数据,确保数据持久化,优化lucene index的写入。
SSD优于HDD
基于时间的索引管理:shrink和rollover shrink api 减少主分片,生成新的索引。只有只读才能收缩。
Elasticsearch源码解析与优化实战
Gradle-TODO
Gradle简介
Book
Gradle实战
Druid-TODO
Druid简介
Spring
Spring Core
container:configuration model + dependency injection
Lightweight and minimally invasive development with POJOs Loose coupling through DI and interface orientation Declarative programming through aspects and common conventions Eliminating boilerplate code with aspects and templates
Spring一个包里面的support都是接口的便利实现。
核心对象
BeanWrapper,PropertiesEditor
BeanFactory,XmlBeanFactory,ListableBeanFactory,DefaultListableBeanFactory
BeanDefinition
ApplicationContext,WebApplicationContext,XmlWebApplicationContext
ContextLoader/ContextLoaderListener/ContextLoaderServlet
ApplicationContext:ClassPathXmlApplicationContext,FileSystemXmlApplicationContext,GenericGroovyApplicationContext 最灵活的方式:GenericApplicationContext
metadata -> bean definition -> bean factory -> applcation context
xxxTemplate(JDBC,JMS)
Resource,AbstractResource,ResourceLoader
BeanDefinitionRegistry,BeanDefinition,
异常处理:受检成运行,捕获能处理
Spring源码先看Interface,在看Interface继承关系,在看AbstractInterface
AbstractInterface里面的protected方法和属性需要注意。没有protected属性,说明不是为了继承而设计的。
spring aop的实现?
spring ioc的实现?
spring 事务的实现?
IOC
instantiating, configuring, and assembling the beans
configuration metadata:XML, Java annotations, or Java code
bean definition:Class,Name,Scope,Constructor arguments,Properties,Autowiring mode,Lazy initialization mode,Initialization method ,Destruction method
autowiring collaborators
FactoryBean 自定义Bean创建 ProxyFactoryBean 代理包装Bean TransactionProxyFactoryBean 事务包装代理
dependencies are on interfaces or abstract base classes, which allow for stub or mock implementations to be used in unit tests
uml里面有association和dependency. 而dependency和ioc dependency不一样,ioc dependency是所有有关联的对象,而不在乎对象来自哪里。 结合起来看,就是依赖注入(IOC)成关联(UML)。
public class A {
}
public class B {
}
public class C { //此时没有办法注入A,B public void doTask(A a,B b){} }
main() { C c = new C(); c.doTask(new A(), new B()); }
这个依赖放在了方法上面了,
AOP
Aspect:跨多个类的模块化横切点 Join point:程序执行的地点。 Advice:程序执行的地方发生的操作。 Pointcut:满足程序执行地点的条件。 Introduction:代表类型声明其他方法或字段 Target object: 被多个Aspect Advice的对象 AOP proxy: Weaving:
join points matched by pointcuts is the key to AOP
auto-proxying
aop is proxy-based frameworks
动态代理失效: AspectJ does not have this self-invocation issue because it is not a proxy-based AOP framework.
Pointcut以及实现.
创建代理方式: Dependency on Spring IoC:ProxyFactoryBean是Spring创建代理的Bean,ProxyFactoryBean通过 Dependency on Programmatically: ProxyFactory Dependency on Auto-proxy:BeanNameAutoProxyCreator,DefaultAdvisorAutoProxyCreator
java代理发展:静态,动态。spring aop框架(可单独使用) java依赖管理:手动,spring ioc容器(可单独使用)
TransactionProxyFactoryBean
Data Access
JDBC,DAO(二级抽象),ORM(JPA,Hibernate),Spring-Data-JDBC,spring-boot-starter-data-jdbc 一级(低级别抽象):一个控制JDBC工作流程和错误处理的框架。 org.springframework.jdbc.core 核心JdbcTemplate 二级(高级别抽象):RDBMS操作建模Java对象操作 - org.springframework.jdbc.object 核心RdbmsOperation ORM:org.springframework.orm
mybatis,spring-mybatis,spring-mybatis-starter
AOP:Advisor=Advice+PointCut
AOP
JavaBean+ProxyFactory=Proxy JavaBean
JavaBean+ProxyFactory+TransactionInterceptor=Proxy Transaction JavaBean
JavaBean+TransactionProxyFactoryBean=Proxy Transaction JavaBean
其他感悟
Spring从来不用别人接口,都是自己定义接口。
Spring源码先读接口和实现类,此垂直为类之职责。在读关联,此水平为类之交互。
Spring WebMVC
SpringWeb
SpringWebMVC
Spring Test
https://github.com/xiaozhiliaoo/spring-test-practice
Spring Boot
https://docs.spring.io/spring-boot/docs/current/reference/html/index.html
看到这里了:https://docs.spring.io/spring-boot/docs/current/reference/html/features.html#features.testing.spring-boot-applications.spring-mvc-tests
Notes
Core
Convention_over_configuration
embed,starter,autoconfigure,production-ready features,no code generation
Project Structure
spring-boot-starter-xxx
spring-boot-xxx-autoconfigure
spring-boot-xxx
springboot的结构 spring-boot-starter spring-boot-autoconfigure spring-boot
springboot-test结构 spring-boot-starter-test(spring-boot-starter) spring-boot-test-autoconfigure spring-boot-test
springboot-actuator结构 spring-boot-starter-actuator(spring-boot-starter) spring-boot-actuator-autoconfigure spring-boot-actuator
Configuration Metadata
配置
Features
Liveness State Readiness StateL
Spring’s Environment abstraction
Database版本化管理:MyBatis Migrations,liquibase,flyway
https://metrics.ryantenney.com/ Spring integration for Dropwizard Metrics
Actuator(运维能力)
文档:https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html
数据通过http/jmx接口暴露
spring-boot-actuator
spring-boot-starter-actuator
spring-boot-actuator-autoconfigure
Health:HealthContributor,HealthIndicator
Information:InfoContributor
Endpoint:和应用检测和交互的点。提供了很多内置的Endpoint.
Actuator Web API:https://docs.spring.io/spring-boot/docs/2.6.4/actuator-api/htmlsingle/#overview
BeansEndpoint,BeansEndpointAutoConfiguration
Endpoint可以通过Http或者JMX暴露出去,这个是怎么实现的呢?
dropwizard,micrometer(Spring Boot 2: Migrating From Dropwizard Metrics to Micrometer)
Auto Configuration
spring-boot-autoconfigure
疑问:
starter里面的autoconfigure是怎么配置第三方库的呢?
mybatis-spring-boot-starter mybatis-spring-boot-autoconfigure mybatis-spring mybatis
spring的autoconfigure的配置类不在原来库代码里面,这是怎么做到的呢?而common-xxx配置类在库实现里面。 以上例子是经典例子, mybatis-spring配置了mybatis,从而在FactoryBean(Spring)获取SqlSessionFactory(MyBatis),是真实的创建了MyBatis的对象的, 但是mybatis-spring-boot-autoconfigure配置了mybatis,也创建对象。这就是自动装配。这一步是通过spring.factories文件实现的。
Spring的配置Bean概念,Configuration(配置的Bean),ConfigurationProperties(配置Bean的属性),autoconfigure指的是自动装配Bean.而在自动 装配过程中,用到了Properties
Spring Boot的设计是加载应用级配置,随后再考虑自动配置类。
单元测试专注于单一组件或组件中的一个方法,此处并不一定要使用Spring。Spring提供了 一些优势和技术——松耦合、依赖注入和接口驱动设计。这些都简化了单元测试的编写。但Spring 不用直接涉足单元测试,集成测试会涉及众多组件,这时就需要Spring帮忙了。
Spring Boot和Grails
HttpTrace默认的类,InMemoryHttpTraceRepository,100条,持久化实现需要继承HttpTraceRepository类
深入Spring Boot应用程序的内部细节:Actuator
ConfigurationProperties和Environment区别?
程序的配置,传入到
Spring Boot Admin
https://codecentric.github.io/spring-boot-admin/
注册方式:Admin Client或者Discovery Client
服务通过Admin Cli ent注册到Admin Server上了。
Service引入Admin Client把自己ip注册到Admin Service,然后Admin Service读取Admin Client的actuator接口?
Admin Client注册的类:ApplicationRegistrator,注册到Admin Server的InstancesController#register方法了。
Admin Server提供了三个Controller来接受请求,InstancesController,ApplicationsController,InstancesProxyController
Admin Server通过InstanceWebClient调用Service. 从而对Service进行控制。
核心实体类:Application,Instance,InstanceEvent(注册,不注册,状态更新,),Registration,InstanceEventStore
注册信息存在了哪里?InstanceEventStore,默认注册在内存中了。
基于事件的注册,将事件注册到内存中。
Spring Cloud Common
https://docs.spring.io/spring-cloud-commons/docs/current/reference/html/
Core Class
SpringApplication SpringApplicationBuilder BootstrapConfiguration
DiscoveryClient ServiceRegistry LoadBalancerClient
Notes
Cloud核心包: Spring Cloud Context and Spring Cloud Commons and Spring Cloud Load Balancer and Circuit breaker
child contexts inherit property sources and profiles from their parent
common patterns: service discovery, load balancing, and circuit breakers
springcloud common loadbalance and spring cloud loadbalance 区别是什么?
common里面提供的接口,并没有提供实现,而spring cloud loadbalance提供了实现。 service discovery/register 实现:consul,zk,eureka load balancing 实现:spring cloud loadbalance circuit breaker实现:Resilience4J,Sentinel,Spring Retry(Spring Cloud Circuit Breaker)
一些新的endpoint,引入了spring-boot-actuator,refresh,restart,pause,env
Refresh入口类是:RefreshEndpoint,RefreshScope实现了GenericScope,GenericScope实现了Scope类, 也就是@RefreshScope是@Scope("refresh")
Spring Cloud Consul
https://cloud.spring.io/spring-cloud-consul/reference/html/
lookup service:
Spring Cloud Config
https://cloud.spring.io/spring-cloud-config/reference/html/
Core Class
Environment
EnvironmentRepository实现类JGitEnvironmentRepository ,通过Eclipse JGit实现
Notes
The Config Server runs best as a standalone application
other external property sources
Config Client:Config First Bootstrap,Discovery First Bootstrap
Spring Cloud Gateway
Spring Cloud OpenFeign
https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
Spring Integration
Spring Others
Book
Spring实战第四版
SpringBoot解密
KVStore
Redis
The world’s most loved real‑time data platform
MapDB
分布式事务
atomikos
seata
Book
深入理解分布式事务
正本清源分布式事务之Seata
Library
apache-httpcomponents
https://hc.apache.org/httpcomponents-client-4.5.x/current/tutorial/html/fluent.html
Logback
apache-poi
Server-Sent-Events
https://en.wikipedia.org/wiki/Server-sent_events
https://www.youtube.com/watch?v=2To3_mYT2hc&t=8s
https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
https://docs.spring.io/spring-framework/docs/current/reference/html/web.html#mvc-ann-async-sse
dom4j
lombok
@Cleanup
logstash-logback-encoder
https://github.com/logfellow/logstash-logback-encoder
jmx
spring对jmx的处理:
step1:在spring-framework里面封装jmx,MBeanExporter,AnnotationMBeanExporter
step2:在spring-autoconfigure中自动配置jmx,JmxAutoConfiguration
step3:在spring-boot-actuator中通过JmxEndpointExporter将endpoint暴露出去,endpoint本身可以通过http和jmx暴露。 spring-boot-actuator-autoconfigure中配置JmxEndpointAutoConfiguration
step4:在spring-boot-admin中通过jolokia暴露所有jmx(endpoint和其他jmx)
https://docs.oracle.com/javase/tutorial/jmx/overview/index.html
https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#jmx
https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.jmx
https://codecentric.github.io/spring-boot-admin/2.5.1/#jmx-bean-management
单元测试
junit5
参数化测试:减少样板代码
API: ExecutionCondition
JUnit Jupiter’s org.junit.jupiter.api.Assertions class does not provide an assertThat() method like the one found in JUnit 4’s org.junit.Assert
Assumptions的作用是什么?
mode:per-class,per-method
@Nested:测试之间的关系以及测试结构
assertj
mockito
Mockito
Mockito
when...thenXXX(not void) ... invoke when...thenAnswer ... ... invoke
doXXX...when (void)... invoke doAnswer...when(void)... invoke
doAnswer使用场景是什么?测试有参数无返回值,无参数无返回值.
BDDMockito
BDDMockito
given...willReturn
verify
Argument matchers ArgumentCaptor
@Mock @Spy @Captor @InjectMocks
SpringBoot: @MockBean @SpyBean
@Mock和@MockBean区别是什么? @Mock和@InjectMocks区别是什么? doAnswer.when和when thenReturn和when thenAnswer和doReturn when区别区别? doAnswer.when返回空,就是void方法。
组合: @Mock和@InjectMock @MockBean和@Autowired
Use doAnswer() when you want to stub a void method with generic Answer.
jacoco
Book
有效的单元测试
Database
MySQL
Redis
资源地址
redis版本
版本的格式:major.minor.patch
Patch-Level versions
Patches primarily consist of bug fixes and very rarely introduce any compatibility issues.
Minor versions
Minor versions usually deliver maturity and extended functionality.
Major versions
Major versions introduce new capabilities and significant changes
版本的维护
Two additional versions receive maintenance only, meaning that only fixes for critical bugs and major security issues are committed and released as patches:
- The previous minor version of the latest stable release.
- The previous stable major release.
Mongdb
Canal
Doris
运维
Tracing
Monitoring
Logging
rancher
kubernetes
harbor
Reacher
aws
aliyun
Replication And Consistency(Not Consensus)
在分布式系统中,复制可用来实现Reliable, Scalable. 数据的复制会导致一致性问题。 数据的复制也即同步过程,会带来节点是否可用问题,这也是CAP中的AP权衡。 复制是一项基础技术,而一致性是这项技术带来的问题。可以认为没有复制便没有一致性问题。
Replication in database,kv,document-db,column-db,file system, distributed coordination,Framework
Replication Model https://en.wikipedia.org/wiki/Replication_(computing)
Consistency Model https://en.wikipedia.org/wiki/Consistency_model
Consistency Model https://jepsen.io/consistency
Database
mysql https://dev.mysql.com/doc/refman/8.0/en/replication.html
postgresql https://www.postgresql.org/docs/current/high-availability.html
mariadb https://mariadb.com/kb/en/standard-replication/
KV store
redis https://redis.io/topics/replication
etcd https://etcd.io/docs/v3.3/faq/
riak https://docs.riak.com/riak/kv/latest/learn/concepts/replication/index.html
tikv: https://tikv.org/deep-dive/scalability/introduction/
dynamo
consul https://www.consul.io/docs/architecture
Document
mongodb https://docs.mongodb.com/manual/replication/
couchdb https://docs.couchdb.org/en/stable/replication/intro.html https://guide.couchdb.org/editions/1/en/replication.html
Framework
hazelcast https://docs.hazelcast.com/imdg/4.2/consistency-and-replication/consistency
akka https://doc.akka.io/docs/akka/current/typed/cluster-concepts.html
Column DB
cassandra https://cassandra.apache.org/doc/latest/cassandra/architecture/overview.html
hbase https://hbase.apache.org/book.html#_cluster_replication
Message
kafka https://kafka.apache.org/documentation/#replication https://cwiki.apache.org/confluence/display/kafka/kafka+replication
rabbitmq https://www.rabbitmq.com/ha.html
rocketmq https://rocketmq.apache.org/docs/rmq-deployment/
activemq https://activemq.apache.org/clustering
Search
elasticsearch https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html
solr https://solr.apache.org/guide/6_6/index-replication.html
File System
hdfs https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#Data+Replication
ceph
GFS
Coordination
zookeeper: https://zookeeper.apache.org/doc/r3.2.2/zookeeperInternals.html
Distributed database(newsql)
yugabyte https://docs.yugabyte.com/latest/architecture/docdb-replication/replication/
CockroachDB https://www.cockroachlabs.com/docs/stable/architecture/replication-layer.html
other
Aurora https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Replication.html
Spanner/F1
rethinkdb https://rethinkdb.com/docs/architecture/
Windows Azure Storage https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy
voldemort https://www.project-voldemort.com/voldemort/design.html
Bigtable
Yahoo PNUTS
VoltDB https://docs.voltdb.com/UsingVoltDB/ChapReplication.php
ScyllaDB https://docs.scylladb.com/architecture/
foundationdb: https://apple.github.io/foundationdb/consistency.html https://apple.github.io/foundationdb/fault-tolerance.html
| Application | Replication Model | Consistency Model |
|---|---|---|
Partitioning&Sharding
分区是将大数据集拆分成小数据集的方法,拆分会带来两个问题,1 是寻找到分区信息Routing 2 是增减节点时候Rebalance分区
https://en.wikipedia.org/wiki/Shard_(database_architecture)
https://en.wikipedia.org/wiki/Partition_(database)
partition:hazelcast,kafka shard:MongoDB,ES,Solr region:Hbase,TiKV tablet:Bigtable vnode:Cassandra,Riak vBucket(virtual buckets):Couchbase slot:Redis ShardRegion:akka
System
Memcached
Redis:https://redis.io/topics/partitioning https://redis.io/topics/cluster-tutorial
Cassandra https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/architecture/archDataDistributeAbout.html https://cassandra.apache.org/doc/latest/cassandra/architecture/dynamo.html#dataset-partitioning-consistent-hashing
DynamoDB
Google Spanner
Shardingsphere
rethinkdb:https://rethinkdb.com/docs/architecture
HBase:https://hbase.apache.org/book.html#manual_region_splitting_decisions https://hbase.apache.org/book.html#regions.arch
BigTable:
MongoDB:https://docs.mongodb.com/manual/sharding/
voldemort: https://www.project-voldemort.com/voldemort/rebalance.html https://www.project-voldemort.com/voldemort/design.html
Couchbase: https://docs.couchdb.org/en/stable/partitioned-dbs/index.html
MySQL:https://dev.mysql.com/doc/refman/8.0/en/partitioning.html
Riak:
voltdb:https://docs.voltdb.com/UsingVoltDB/IntroHowVoltDBWorks.php
HDFS:https://blog.cloudera.com/partition-management-in-hadoop/
Ketama https://www.metabrew.com/article/libketama-consistent-hashing-algo-memcached-clients
Request Routing
service discovery
https://helix.apache.org/
https://docs.mongodb.com/manual/core/sharded-cluster-config-servers/
https://github.com/couchbase/moxi
Rebalancing(Split&Merge)
StorageEngine
MySQL:https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html
Postgre:https://wiki.postgresql.org/wiki/Future_of_storage
Mariadb:https://mariadb.com/kb/en/choosing-the-right-storage-engine/
cassandra: https://cassandra.apache.org/doc/latest/cassandra/architecture/storage_engine.html
riak:https://docs.riak.com/riak/kv/2.2.3/setup/planning/backend/bitcask/index.html
consul,etcd:blot
leveldb:https://github.com/google/leveldb/blob/main/doc/impl.md
rocksdb:http://rocksdb.blogspot.com/
hbase:https://hbase.apache.org/book.html#inmemory_compaction
elasticsearch:lucene,https://www.elastic.co/cn/blog/found-dive-into-elasticsearch-storage
solr:lucene
lucene:https://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html
lmdb:http://www.lmdb.tech/doc/
voltdb:
memsql:
ramcloud:
redis:
mongodb:https://docs.mongodb.com/manual/core/storage-engines/
couchbase:
OLAP:Teradata,Vertica,SAP HANA,ParAccel,Amazon RedShift
Apache Hive,SparkSQL,Cloudear Impala,Facebook Presto,Aoache Tajo,Apache Drill,Google Gremel
Network Partition
https://en.wikipedia.org/wiki/Network_partition
https://en.wikipedia.org/wiki/Split-brain
akka:https://doc.akka.io/docs/akka-enhancements/current/split-brain-resolver.html
hazelcast: https://docs.hazelcast.com/imdg/4.2/network-partitioning/split-brain-protection https://hazelcast.com/blog/jepsen-analysis-hazelcast-3-8-3/
es: https://www.elastic.co/guide/en/elasticsearch/reference/8.0/modules-discovery-quorums.html https://www.elastic.co/guide/en/elasticsearch/reference/8.0/modules-discovery-voting.html https://www.elastic.co/guide/en/elasticsearch/reference/8.0/high-availability-cluster-design-large-clusters.html https://www.elastic.co/guide/en/elasticsearch/reference/8.0/high-availability-cluster-small-clusters.html
CouchDB: https://guide.couchdb.org/editions/1/en/conflicts.html
rabbitmq: https://www.rabbitmq.com/partitions.html
Transaction
https://en.wikipedia.org/wiki/Isolation_(database_systems)
aerospike:https://aerospike.com/blog/developers-understanding-aerospike-transactions/
datomic: https://docs.datomic.com/on-prem/transactions/transactions.html
MySQL:https://dev.mysql.com/doc/refman/8.0/en/innodb-locking-transaction-model.html
PostgreSQL:https://www.postgresql.org/docs/14/mvcc.html K Oracle
SQL Server2012: https://docs.microsoft.com/en-us/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide?view=sql-server-ver15#database-engine-isolation-levels
FoundationDB:https://apple.github.io/foundationdb/transaction-manifesto.html
Access
MemSQL(singlestore):https://dbdb.io/db/singlestore
Index
https://en.wikipedia.org/wiki/Database_index
ResiliencyPatterns
Retry
https://github.com/elennick/retry4j
Guava Retry
Spring Retry
resilience4j-retry
https://failsafe.dev/
ServiceRegistry
https://microservices.io/patterns/service-registry.html
服务注册和发现是分布式系统里面的Naming部分,并不是Communication部分。Communication是Feign做的。
nacos,zookeeper,etcd,consul,eureka
nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
zookeeper:Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
etcd:A distributed, reliable key-value store for the most critical data of a distributed system
consul:Consul is a service networking solution to automate network configurations, discover services, and enable secure connectivity across any cloud or runtime.
eureka:Eureka is a RESTful (Representational State Transfer) service that is primarily used in the AWS cloud for the purpose of discovery, load balancing and failover of middle-tier servers. It plays a critical role in Netflix mid-tier infra.
Person
Peter Bailis: HAT,Consistency Model
技术分享
Kafka-Architect
内容列表
kafka引入
AKF原则
kafka架构
代码演示
可靠性保证
kafka引入
kafka是什么?
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafka is an event streaming platform used to collect, process, store, and integrate data at scale. It has numerous use cases including distributed streaming, stream processing, data integration, and pub/sub messaging.
重点:不只是分布式消息中间件,还是分布式流式消息(事件)处理平台
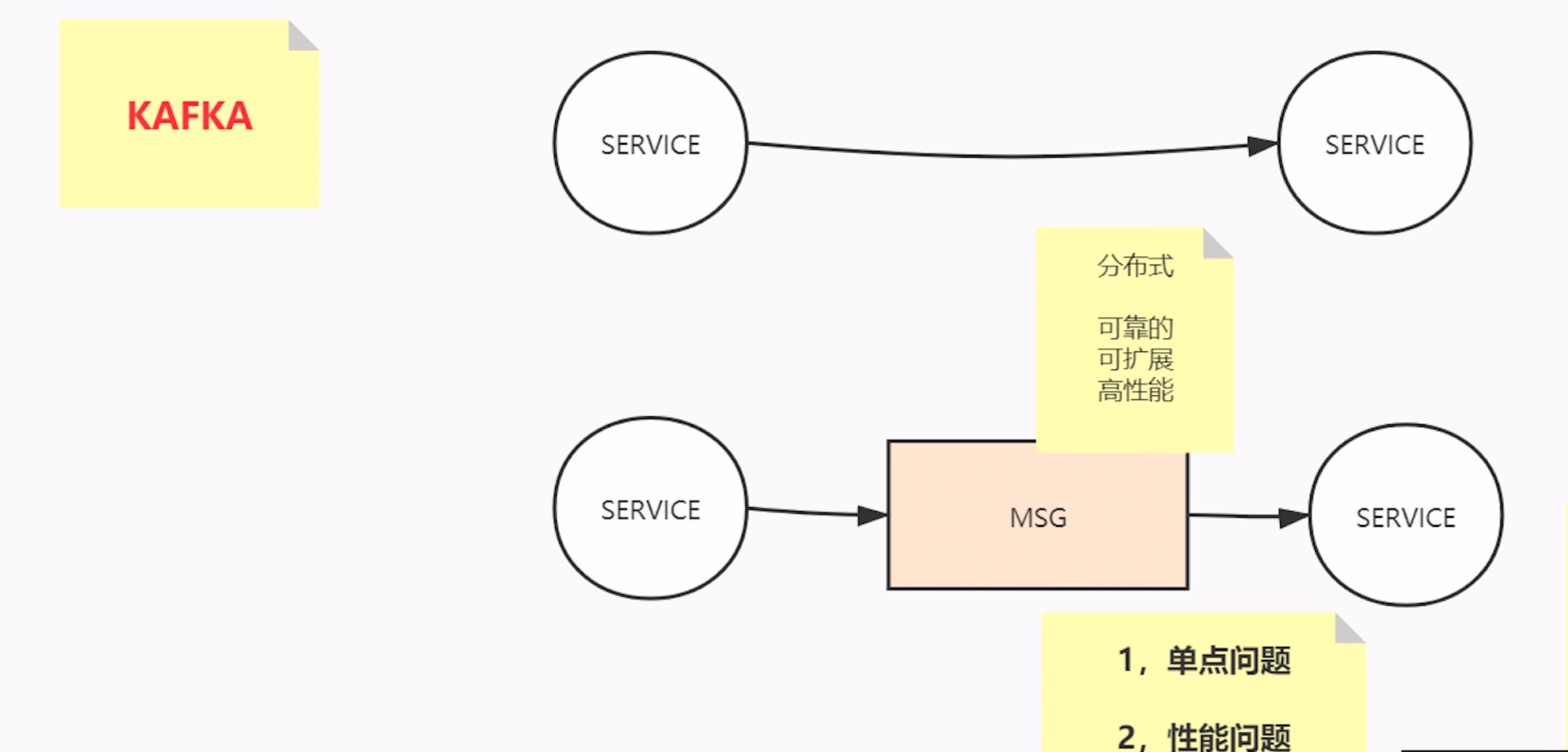
单体到分布式,引入的问题:可靠性、可扩展性、高性能
AKF原则
AKF 立方体也叫做scala cube,它在《The Art of Scalability》一书中被首次提出,旨在提供一个系统化的扩展思路。AKF 把系统扩展分为以下三个维度:
- X 轴:直接水平复制应用进程来扩展系统。(比如单体服务,但部署时一发动全身)
- Y 轴:将功能拆分出来扩展系统。(拆分微服务,但好的业务迟早会遇见数据瓶颈)
- Z 轴:基于用户信息扩展系统。(数据分区,比如分库分表)
Kafka AKF分析
x轴,对parttion进行副本备份,副本(理论上可以读写分离,但容易出现一致性问题,干脆只能在主P上进行读写)
y轴:topic,不同的业务使用不同topic
z轴:partiton,对无关的数据打散到不同的分片,分而治之。将相关的数据按顺序聚合到同一个分片
Kafka数据处理思路
无关的数据,必然分治——>无关的数据就分散到不同的分区里,以追求并发并行
有关的数据,聚合——> 有关的数据,一定要按原有顺序发送到同一分区里
分区内部有序,分区外部无序
kafka架构
核心组件:Zookeeper、Broker、Topic、Partition、Producer、Consumer(group)
Zookeeper
单机管理->主从集群 分布式协调,zk不用于存储(相当于服务网关,负责路由转发)
旧版本
producer是通过zookeeper获取集群节点信息的,zk除了是个协调以外,还是个存储DB,offset是维护在zookeeper当中
新老版本的区别
角色之间通信,producer和consumer面向的是broker,在业务层次上不再依赖zookeeper(减少zk的负载),只是个协调
元数据Metadata:topic,partition,broker
kafka架构图
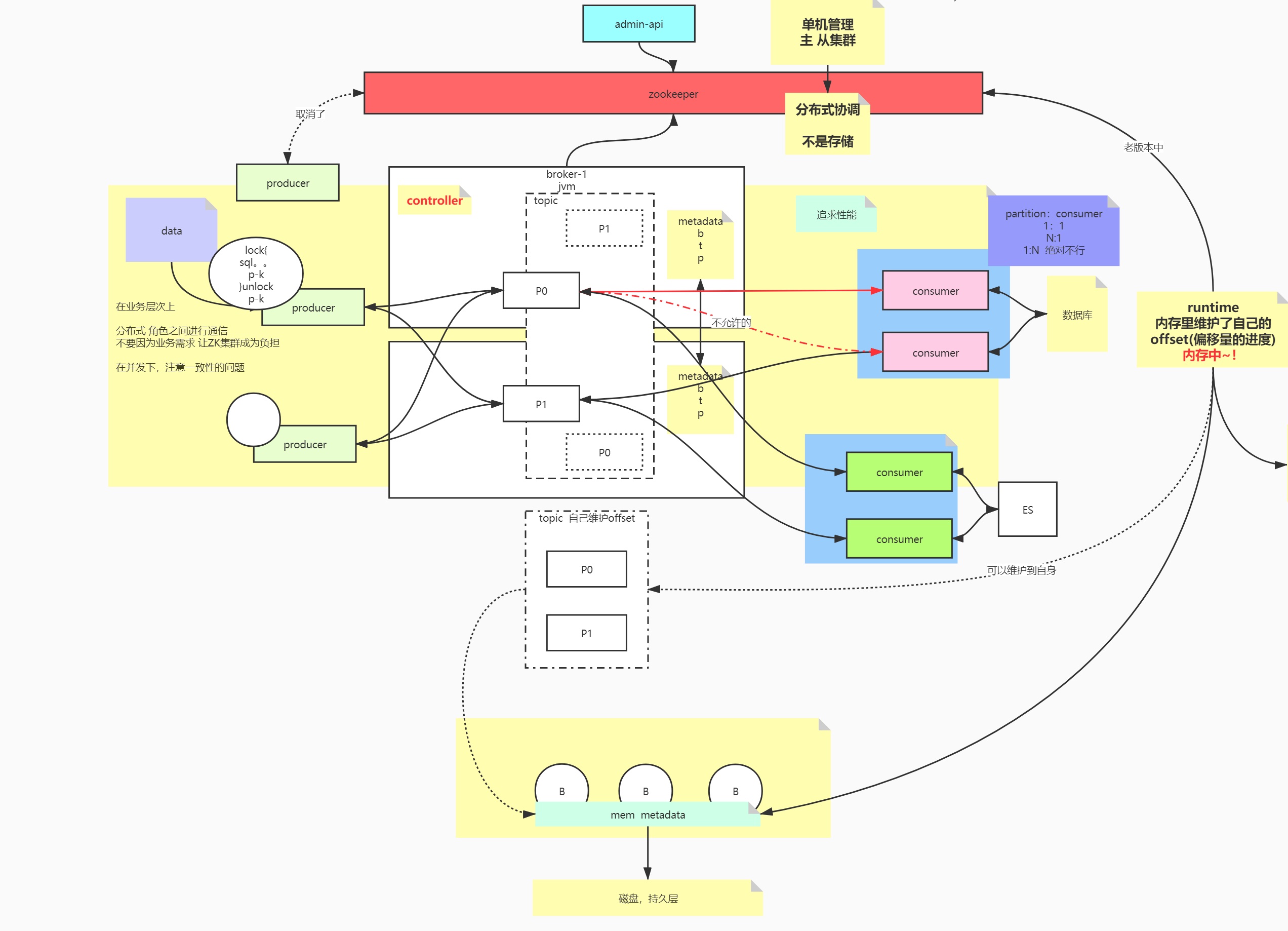
核心组件的关系
broker与zookeeper的关系?
broker与partition的关系?
创建一个topic的过程
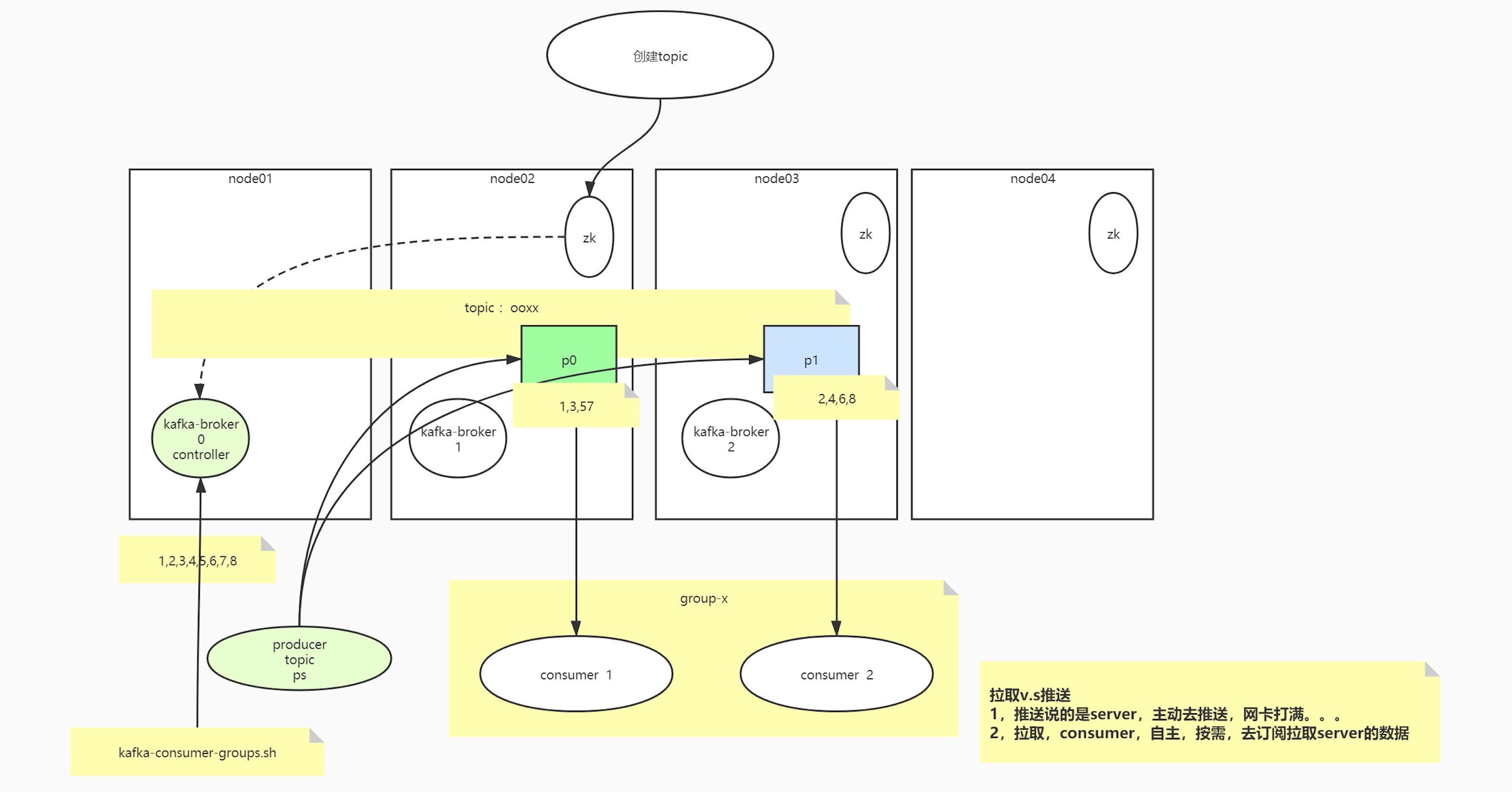
Producer
在并发情况下,注意一致性(顺序性保证)的问题
lock() {
sql
producer.produce()
} unlock();
生产的数据保存在哪里?
kafka的broker的partition里
Consumer
consumer与patition的关系:1:n/ 1:1
思考,consumer与patition的关系n:1可不可以?
破坏有序性
group
不同业务组之间,需要消费同一topic的数据,可以使用不同的group
在单一的使用场景下,先要保证,即便追求性能,用多个consumer,应该注意,不能一个分区由多个consumer消费
数据的重复利用是站在group上
offset
比如consumer重启,会不会导致数据重复消费和丢失,围绕的是消费的进度offset
起初consumer在runtime里维护自身的consumer,旧版本的offset是通过consumer与zookeeper通信维护的
新版kafka能自己维护offset,维护在topic当中,consumer->broker(runtime)->mem metadata->磁盘,持久层
offset的两种提交方式
-
自动提交:每间隔5s,先处理业务逻辑,异步提交offset,重复消费
-
手动提交:处理业务逻辑,同步提交offset
自动异步提交时(默认每5s提交一次),导致的问题?
- 重复消费&消息丢失
- 场景
- 还没到时间,挂了,没提交,重起一个consumer,参照offset的时候,会重复消费。
- 一个批次的数据还没写数据库成功,但是这个批次的offset被异步提交了,挂了,重起一个consumer,参照offset的时候,会导致消息丢失。
代码演示
实战
生产者消费者代码
可靠性保证
可靠性是系统的⼀个属性,⽽不是⼀个独⽴的组件,所以在讨论 Kafka 的可靠性保证时,还是要从系统的整体出发。
可靠性保证
只有当消息被写⼊分区的所有同步副本时(但不⼀定要写⼊磁盘),它才被认为是“已提交”的。
broker配置
broker 有 3 个配置参数会影响 Kafka 消息存储的可靠性。
复制系数
replication.factor,主题级别的配置参数,因为 Kafka 的默认复制系数就是 3——不过⽤户可以修改它。即使是在主题创建之后,也可以通过新增或移除副本来改变复制系数。
如果复制系数为 N,那么在 N-1 个 broker 失效的情况下,仍然能够从主题读取数据或向主题写⼊数 据。所以,更⾼的复制系数会带来更⾼的可⽤性、可靠性和更少的故障。另⼀⽅⾯,复制系数 N 需要 ⾄少 N 个 broker,⽽且会有 N 个数据副本,也就是说它们会占⽤ N 倍的磁盘空间。我们⼀般会在可⽤性和存储硬件之间作出权衡。
副本的分布也很重要。默认情况下,Kafka 会确保分区的每个副本被放在不同的 broker 上。
不完全的⾸领选举
unclean.leader.election.enable只能在 broker 级别(实际上是在集群范围内)进⾏配置,它的默认值是 true。
我们之前提到过,当分区⾸领不可⽤时,⼀个同步副本会被选为新⾸领。如果在选举过程中没有丢失数据,也就是说提交的数据同时存在于所有的同步副本上,那么这个选举就是“完全”的。 但如果在⾸领不可⽤时其他副本都是不同步的,我们该怎么办呢?
简⽽⾔之,如果我们允许不同步的副本成为⾸领,那么就要承担丢失数据和出现数据不⼀致的⻛险。 如果不允许它们成为⾸领,那么就要接受较低的可⽤性,因为我们必须等待原先的⾸领恢复到可⽤状态。
如果把 unclean.leader.election.enable 设为 true,就是允许不同步的副本成为⾸领(也就 是“不完全的选举”),那么我们将⾯临丢失消息的⻛险。如果把这个参数设为 false,就要等待原先的⾸领重新上线,从⽽降低了可⽤性。
两种场景:银行系统,信用卡支付事务/实时点击流分析系统
最少同步副本
在主题级别和 broker 级别上,这个参数都叫 min.insync.replicas。
根据 Kafka 对可靠性保证的定义,消息只有在被写⼊到所有同步副本之后才被认为是已提交的。
对于 ⼀个包含 3 个副本的主题,如果 min.insync.replicas 被设为 2,那么⾄少要存在两个同步副本 才能向分区写⼊数据。 如果 3 个副本都是同步的,或者其中⼀个副本变为不可⽤,都不会有什么问题。不过,如果有两个副 本变为不可⽤,那么 broker 就会停⽌接受⽣产者的请求。尝试发送数据的⽣产者会收到 NotEnoughReplicasException 异常。消费者仍然可以继续读取已有的数据。实际上,如果使⽤ 这样的配置,那么当只剩下⼀个同步副本时,它就变成只读了,这是为了避免在发⽣不完全选举时数 据的写⼊和读取出现⾮预期的⾏为。为了从只读状态中恢复,必须让两个不可⽤分区中的⼀个重新变 为可⽤的(⽐如重启 broker),并等待它变为同步的。
在可靠的系统⾥使⽤⽣产者
- 根据可靠性需求配置恰当的 acks 值。
- 在参数配置和代码⾥正确处理错误。
acks(0,1,all)
⼀般情况下,如果你的⽬标是不丢失任何消息,那么最好让⽣产者在遇到可重试错误时能够保持重试。
重试发送⼀个已经失败的消息会带来⼀些⻛险,如果两个消息都写⼊成功,会导致消息重 复。重试和恰当的错误处理可以保证每个消息“⾄少被保存⼀次”,但当前 的 Kafka 版本(0.10.0)⽆法保证每个消息“只被保存⼀次”。
在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture)或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
所谓的消息交付可靠性保障,是指 Kafka 对 Producer 和 Consumer 要处理的消息提供什么样的承诺。常见的承诺有以下三种:
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
使⽤⽣产者内置的重试机制可以在不造成消息丢失的情况下轻松地处理⼤部分错误,不过对于开发⼈员来说,仍然需要处理其他类型的错误,包括:
- 不可重试的 broker 错误,例如消息⼤⼩错误、认证错误等;
- 在消息发送之前发⽣的错误,例如序列化错误;
- 在⽣产者达到重试次数上限时或者在消息占⽤的内存达到上限时发⽣的错误
- 丢弃“不合法的消息”?
- 把错误记录下来?
- 把这些消息保存在本地 磁盘上?
- 回调另⼀个应⽤程序?
具体使⽤哪⼀种逻辑要根据具体的架构来决定。只要记住,如果错误处理只是为了重试发送消息,那么最好还是使⽤⽣产者内置的重试机制。
在可靠的系统⾥使⽤消费者
group.id:消费者组id
auto.offset.reset:(earliest/latest)
enable.auto.commit:(自动提交/手动提交)
auto.commit.interval.ms:自动提交的时间间隔
手动提交offset
错误重试,超过重试次数,就写入三方组件
仅⼀次传递:幂等性写⼊
总结
可靠性并不只是 Kafka 单⽅⾯的事情,我们应该从整个系统层⾯来考虑 可靠性问题,包括应⽤程序的架构、⽣产者和消费者 API 的使⽤⽅式、⽣产者和消费者的配置、主题 的配置以及 broker 的配置。
系统的可靠性需要在许多⽅⾯作出权衡,⽐如复杂性、性能、可⽤性和 磁盘空间的使⽤。掌握 Kafka 的各种配置和常⽤模式,对使⽤场景的需求做到⼼中有数,你就可以在 应⽤程序和 Kafka 的可靠性程度以及各种权衡之间作出更好的选择。
参考资料
参考资料
Akka
优先看:https://academy.lightbend.com/
其次:classic: https://doc.akka.io/docs/akka/current/index-classic.html
typed:https://doc.akka.io/docs/akka/current/
API文档:https://doc.akka.io/api/ JAPI:https://doc.akka.io/japi/akka/2.6/akka/actor/AbstractActor.html
AKKA中文指南:https://www.bookstack.cn/read/guobinhit-akka-guide/711c3ba85a66f758.md
http://jasonqu.github.io/akka-doc-cn/2.3.6/scala/book/index.html
快速开始demo:https://developer.lightbend.com/start/?group=akka
代码示例:https://github.com/akka/akka-samples
https://github.com/typesafehub/activator-akka-java-spring https://github.com/lightbend
Akka 响应式架构 https://book.douban.com/subject/26829063/
Akka实战:Akka实战:快速构建高可用分布式应用 https://book.douban.com/subject/30218333/
Akka入门与实践 https://book.douban.com/subject/27055163/
Akka实战 https://book.douban.com/subject/30431012/
TTT:【技术分享】Akka入门与精品课教务系统分布式实战 http://training.corp.youdao.com/play.php?id=139
官方文档 https://doc.akka.io/docs/akka/current/typed/guide/index.html
akka生态:https://akka.io/docs/
https://developer.lightbend.com/docs/akka-platform-guide/index.html
使用akka开发微服务:https://developer.lightbend.com/docs/akka-platform-guide/microservices-tutorial/index.html
lightbend academy: https://academy.lightbend.com/courses
EBOOK: https://www.lightbend.com/akka-platform/resources
Consul
官方文档 https://www.consul.io/docs
生态:https://www.hashicorp.com/
Hazelcast
优先看:https://training.hazelcast.com/
官方文档IMDG https://hazelcast.org/imdg/docs/
https://docs.hazelcast.com/imdg/latest/getting-started.html
hazelcast文档:https://docs.hazelcast.com/hazelcast/5.1/
hazelcast mc文档:https://docs.hazelcast.com/management-center/latest/getting-started/overview
代码示例:https://github.com/hazelcast/hazelcast-code-samples
https://github.com/hazelcast/hazelcast/wiki
Quick Start:https://hazelcast.org/imdg/?samplelang=Java+Member&sampleindex=0
Mastering Hazelcast https://odoepner.files.wordpress.com/2015/04/mastering_hazelcast1.pdf
最新版本:https://hazelcast.com/resources/mastering-hazelcast/
官方文档PDF https://docs.hazelcast.org/docs/4.0.1/manual/pdf/index.pdf
Jackson
https://github.com/FasterXML/jackson-docs
https://github.com/FasterXML/jackson
https://github.com/FasterXML
ElasticSearch
优先看oreilly出版的《ElasticSearch权威指南》
中文版:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html(中文有些esquery写的不对,需要辅助英文的看)
英文版:https://www.elastic.co/guide/en/elasticsearch/guide/master/index.html
https://www.elastic.co/guide/index.html
ElasticSearch Elasticsearch源码解析与优化实战 https://book.douban.com/subject/30386800/
Elasticsearch实战 https://book.douban.com/subject/30380439/
深入理解ElasticSearch https://book.douban.com/subject/27066928/
官方文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
极客时间 62.极客时间-Elasticsearch核心技术与实战
模型:https://dbdb.io/db/elasticsearch
Elasticsearch:权威指南 : https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/index.html
Elasticsearch: The Definitive Guide: A distributed real-time search and analytics engine
IR:https://nlp.stanford.edu/IR-book/information-retrieval-book.html
Kafka
优先看:https://developer.confluent.io/ course:https://developer.confluent.io/learn-kafka/ 其次:https://kafka.apache.org/ 以及 https://cwiki.apache.org/confluence/display/KAFKA/Index
API:https://kafka.apache.org/30/javadoc/index.html
https://kafka.apache.org/30/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html
https://kafka.apache.org/30/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html
Kafka 深入理解Kakfa核心设计与实践原理 https://book.douban.com/subject/30437872/
Apache Kafka源码剖析 https://book.douban.com/subject/27038473/
Apache Kafka实战 https://book.douban.com/subject/30221096/
Kafka权威指南 https://book.douban.com/subject/27665114/
Kafka Streams实战 https://book.douban.com/subject/33425155/
官方文档 https://kafka.apache.org/documentation/#gettingStarted
https://jaceklaskowski.gitbooks.io/mastering-kafka-streams/content/
Canal
Canal 官方文档 https://github.com/alibaba/canal
Gradle
Gradle Gradle实战 https://book.douban.com/subject/26609447/ 官方文档 https://docs.gradle.org/current/userguide/userguide.html
MapDB
官方文档:https://mapdb.org/
https://dbdb.io/db/mapdb
mapdb作者youtube:https://www.youtube.com/user/jankotek
Seata
深入理解分布式事务 冰河
正本清源分布式事务之Seata
Github Repository
https://github.com/xiaozhiliaoo/akka/tree/akka-practice
https://github.com/xiaozhiliaoo/elasticsearch/tree/es-practice
https://github.com/xiaozhiliaoo/kafka/tree/kafka-practice
https://github.com/xiaozhiliaoo/hazelcast/tree/hazelcast-practice
圣经频道
📖 圣经故事有声平台
你是否曾翻开圣经,却被繁多的章节、古老的背景拦住脚步?是否想探寻其中的智慧,却不知从何切入?
其实,圣经从不只是一本厚重的典籍,而是由一个个鲜活生命串联起的奇妙故事——有信心的先祖、勇敢的先知、舍己的仆人,还有那位改变世界的救赎主。
这一次,我们不想用复杂的神学理论拉开距离,而是选择以「人」为钥匙,为你打开理解圣经的大门。我们从新旧约中精选了31个核心人物故事:
从偷吃禁果的亚当,到救恩的挪亚方舟
从呼召亚伯兰离开本族本家,到摩西带领选民穿越红海
从大卫用小石子战胜巨人,到以赛亚预言「有一婴孩为我们而生」
从耶稣在加利利海边呼召门徒,到保罗跨越山海传讲真理……
每一个故事,都是圣经宏大叙事里的重要篇章。这些故事里,有选民的挣扎与信靠,有危难中的等候与得胜,更有神始终不变的应许与带领。
圣经故事1-6【创世纪篇】
亚当
第一个有灵的活人
挪亚
方舟的救恩
亚伯拉罕
信心之父
以撒
神赐的孩子
雅各
抓住福分的以色列
约瑟
埃及的宰相人生
📖 圣经故事有声平台{.centered}
你是否曾翻开圣经,却被繁多的章节、古老的背景拦住脚步?是否想探寻其中的智慧,却不知从何切入?
其实,圣经从不只是一本厚重的典籍,而是由一个个鲜活生命串联起的奇妙故事——有信心的先祖、勇敢的先知、舍己的仆人,还有那位改变世界的救赎主。
这一次,我们不想用复杂的神学理论拉开距离,而是选择以「人」为钥匙,为你打开理解圣经的大门。我们从新旧约中精选了31个核心人物故事:
从偷吃禁果的亚当,到救恩的挪亚方舟
从呼召亚伯兰离开本族本家,到摩西带领选民穿越红海
从大卫用小石子战胜巨人,到以赛亚预言「有一婴孩为我们而生」
从耶稣在加利利海边呼召门徒,到保罗跨越山海传讲真理……
每一个故事,都是圣经宏大叙事里的重要篇章。这些故事里,有选民的挣扎与信靠,有危难中的等候与得胜,更有神始终不变的应许与带领。
圣经故事1-6【创世纪篇】
亚当
第一个有灵的活人
挪亚
方舟的救恩
亚伯拉罕
信心之父
以撒
神赐的孩子
雅各
抓住福分的以色列
约瑟
埃及的宰相人生