
引言
我们熟知,一般数组和链表不能满足我们常用的业务场景,比如说,我想存一种key-val类型的数据结构,其实来说,ArrayList也可以看成一种简单的哈希结构,只是key只能取int类型。那么为什么要有哈希结构呢?就是为了弥补数组与链表之间查询与修改的性能存在问题。
基于数组的顺序表ArrayList 由于占用的是一块连续的内存,故查询修改较快,插入删除较慢。基于Node节点的双向链表LinkedList 由于当前节点指向下一节点的方式,各个节点在内存中不是连续的,故插入删除较快,查询修改较慢。
为了弥补这两种数据结构的短板,哈希结构的数据类型应运而生,最先开始的是Hashtable,由于当时考虑到线程安全,这个类一上来就加synchronized锁,加锁必然消耗性能,但是,我们更多场景的是不需要锁的,所以才有了HashMap。HashMap是一个性能很不错的哈希表,但是线程不安全的。后来又有了线程安全的ConcurrentHashMap,并且他俩在jdk1.8进行了一次较大的升级,接下来的文章,我们就根据jdk1.7 和 jdk1.8 的源码来分析一下 HashMap 和ConcurrenthashMap。
HashMap
jdk1.7
结构
初始化
1 | public HashMap() { |
实例变量
1 |
|
java1.7 的hashMap结构如下图:
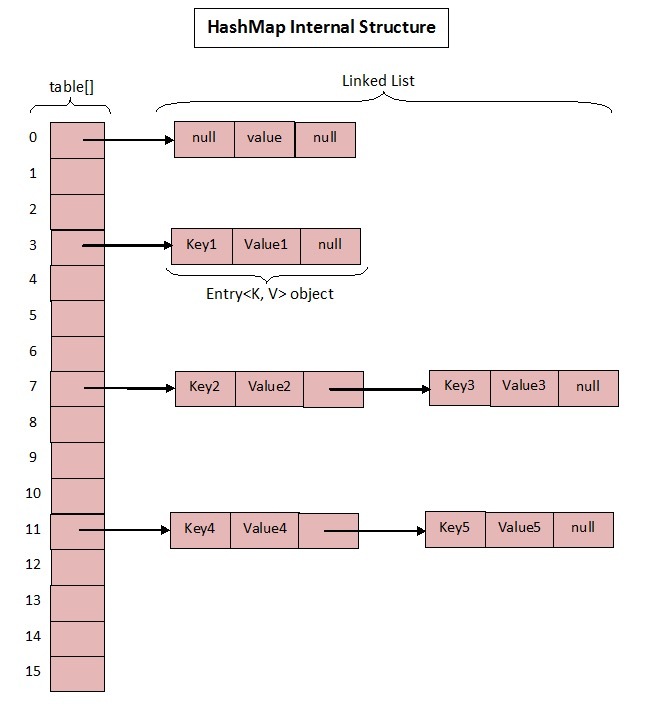
Entry结构
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
put方法
思考:往HashMap 添加1000个元素需要扩容多少次? (Add first)—> 16 —>以后都是两倍的扩容210=1024 ,还需要6次扩容
1 | public V put(K key, V value) { |
addEntry方法
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
createEntry方法
1 | // 插入元素时,应插入哈希桶的头部,而不是尾部 |
resize方法
1 | void resize(int newCapacity) { |
get方法
1 | public V get(Object key) { |
getEntry方法
1 | final Entry<K,V> getEntry(Object key) { |
hash方法
1 | final int hash(Object k) { |
indexFor方法
1 | static int indexFor(int h, int length) { |
remove(key)方法
1 | public V remove(Object key) { |
并发问题
对象丢失问题
1 | public class MapApplication { |
通过程序发现,当每个线程添加元素数据量在1000时,得到的结果并不是2000,而总是小于2000。
说明并发情况下,会导致数据丢失的问题。导致的原因之一是在createEntry方法中的第一处,一个线程的赋值被另一个线程的覆盖了。
同时在resize方法的第二处和第三处也会导致数据丢失。第二处遍历的时候如果有另一个线程将数据插入到已经遍历的桶里面,在步骤(第三处)赋值完也会导致数据丢失。
同时,如果两个线程同时进入到resize的(第四处)代码,newTable = new Entry[newCapacity],由于是局部变量线程不可见,在resize完赋值之后会覆盖其他线程的操作,导致在“新表”中插入的元素无情的丢失。
原因总结
- 并发赋值时被覆盖
- 已遍历区间新增元素会丢失
- “新表”被覆盖
当数据量在100000时,执行程序就不能永远退出,是因为扩容的时候导致死链的问题。
死链问题
1 | public class ResizeMapApplication { |
根据源码可以追踪扩容前内部元素的情况
由于所有的元素都会位于table[1]的哈希桶里,所以只需跟踪table[1]的元素
扩容前:数组的长度为16,阀值为12
12—>11—>10 … … —>2—>1
扩容后:数组的长度为32,阀值为24
13—>1—>2—>3… —>11—>12
当两个线程同时进入resize方法的第二处时,会重新rehash每一个哈希桶里的元素,具体实现如下:
1 | void transfer(Entry[] newTable, boolean rehash) { |
产生问题的根源是next的指针被并发线程修改。
jdk1.8
在jdk1.8中,HashMap做了比较大的升级,关于升级的内容我们通过源码来验证一下。
- jdk1.7是先扩容,再插入元素。而jdk1.8是,先插入元素,再扩容。
- jdk1.7HashMap当链表长度过长时,存在遍历性能的问题。jdk1.8引入了红黑树,解决了该问题。
- jdk1.7扩容时,哈希桶里的元素会重新rehash,顺序会颠倒。而jdk1.8是不一样的。
结构
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
put方法
1 | public V put(K key, V value) { |
hash方法
1 | static final int hash(Object key) { |
putVal方法
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { |
可以看到,在jdk1.8中
- jdk1.8是,先插入元素,再扩容。
- 引入了红黑树,且哈希槽里放的是树的TreeNode结构
- 如果哈希桶是链表结构,长度不大于8的话,则追加的节点在链表的末尾。
到此,验证一、验证二 已经得到验证,现在来验证三。
resize方法
1 | final Node<K,V>[] resize() { |
jdk1.8中在计算新位置的时候并没有跟1.7中一样重新进行hash运算,而是用了原位置+原数组长度这样一种很巧妙的方式,而这个结果与hash运算得到的结果是一致的,只是会更快。
get方法
1 | public V get(Object key) { |
getNode方法
1 | final Node<K,V> getNode(int hash, Object key) { |
简单总结下 HashMap:无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至 1.7 中出现死循环导致系统不可用(1.8 已经修复死循环问题)
ConcurrentHashMap
jdk1.7
由于HashMap是线程不安全的,在多线程下会出现安全问题,故引入了ConcurrentHashMap,支持多并发的场景。
结构
1 | static final int MIN_SEGMENT_TABLE_CAPACITY = 2; |
java1.7 的ConcurentHashMap结构如下图:
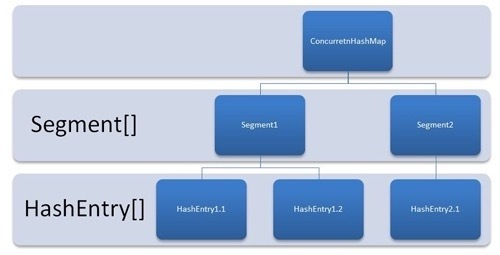
初始化
1 | // 无参构造方法 默认值分别为:16,0.75,16 |
get方法
1 | public V get(Object key) { |
get方法是非常高效的,因为没有加锁。是通过HashEntry的value加了volatile修饰符,保证了内存的可见性。
put方法
1 | public V put(K key, V value) { |
Segment.put方法
1 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
remove方法
1 | public V remove(Object key) { |
Segment.remove方法
1 | final V remove(Object key, int hash, Object value) { |