
引言
今天在上班的路上,想到一个例子,就是一个病人感染上了新冠病毒要上医院去住院隔离治疗,方舱医院如果床位不够,就会导致医院响应不了病人的请求,只能拒绝。但是要能够响应又得临时搜集资源、组建材料搭建病房和床位,这必然会消耗大量的时间,也会耽搁了病人的病情。那么,要是实现了床足够多,达到床等人的话,就能够迅速的接待病人,进行隔离治疗,使病情得到及时的控制。
这个例子让我想到了线程池,假设对服务器的每一个请求都是一个任务调度,当大量的请求过来的时候,必然由于服务器空间资源限制,导致服务器响应缓慢,更可能导致系统崩溃。当大量的请求处理完之后,线程也就会销毁掉,当下次请求再来的时候,又得去创建线程,导致不必要的系统开销,同时降低了系统的响应速度。如果,我们能够在服务器预备一个专门响应的线程池,当请求来的时候我只要取一个线程去处理任务,处理完之后,我不销毁又放回到池子中,这样的话,我就能随到随取。我还想使这个池子有一定的可塑性,当大量的请求过来的时候,我想使更多的线程去响应,但当处理完之后,该销毁的销毁,不该销毁的还留在池子中,这样能同时响应的请求就更多了。当然,当服务器请求处理不过来,我也可能不想把这个请求给扔掉,我想我处理完后,再来处理之后的请求,只是可能需要你等一等!
好吧,这就是我们今天要讲的线程池了。
好处
- 降低资源消耗。避免反复创建线程而不必要的资源开销。
- 提高响应速度。随来随用,当任务到来无需创建线程就能立即响应。
- 提高线程的可管理性。控制系统的最大并发数,避免线程创建过多导致系统运行缓慢甚至崩溃的情况发生,同时可以对线程池统一分配、调优和监控。
思考
- 线程池如何定义?线程池的种类?缓冲队列有哪几种?饱和策略有哪些?这几种线程池该如何使用?
- 当线程池刚刚创立还没有Task到来的时候,线程池中的线程处于什么状态?
- 当Task到来的时候,线程池中的线程是如何得到通知的?
- 当线程池中的线程完成工作,如何回到池子里?
- Task是什么东西?
基本概念
线程池接口
线程池中定义了几个重要的接口,分别是Executor、ExecuterService。
Executor叫做执行者,有execute(Runnable command)方法。
1 | public interface Executor { |
而ExecuterService继承了Executer,定义了线程池对线程的生命周期管理方法,重要的是它还提供了一套submit提交任务的机制。submit表示将任务提交给线程池,至于什么时候执行我就不管了,所以任务执行是异步的。
1 | public interface ExecutorService extends Executor { |
我们知道Runnable没有返回值,但是当我需要返回值的话,那就应该使用Callable接口。
1 |
|
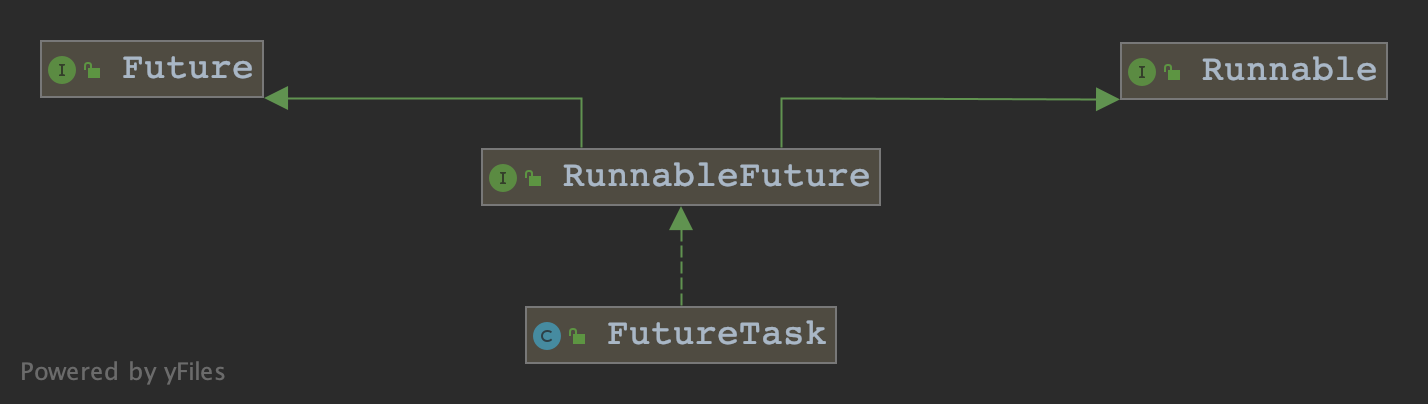
当任务异步执行完后 ,我该如何通知给调用方呢,这就牵扯出一套Future、RunnableFuture和FutureTask相关概念了。
submit方法返回的是一个Future接口,可理解为未来执行完的一个结果,这个接口里面定义了get方法,主线程可以通过调用get()方法拿到任务的执行结果。所以Callable一般是配合线程池和Future来用的。
但是,更加灵活的一种方式,我们可以把Callable和Future进行封装到一个类里面,这个类就是FutureTask,代表的是我即是一个Task也能是一个用来存这个任务的结果的对象,因此,我就得有任务可执行的属性。因为FutureTask实现了RunableFuture,而RunnableFuture即实现了Runnable又实现了Future。
类图如下:
1 | public class T05_Callable { |
注意:主线程调用get方法,任务没有执行完时会被阻塞,直到任务执行完或者抛异常结束。当然,可以指定最大阻塞时间V get(long timeout, TimeUnit unit),当时间到了就不继续等待了,但是会抛出TimeoutException异常。
线程池定义
目前jdk定义的线程池有两种类型,第一种是是普通的线程池ThreadPoolExecutor,第二种是ForkJoinPool,这篇文章我们先分析一下ThreadPoolExecutor相关的线程池。
ThreadPoolExecutor的父类是AbstractExecutorService,而AbstractExecutorService是个抽象类,主要实现了ExecutorService的submit方法,上面知道,ExecutorService也继承了Executor。所以,ThreadPoolExecutor相当于线程池的执行器,可以往这个池子里面扔要执行的任务。
类图如下:

那么,ThreadPoolExecutor是如何定义的呢,它的核心参数如下:
1 | /** |
corePoolSize:核心线程数
maximumPoolSize:最大线程数
keepAliveTime:线程的空闲时间,超出这个时间,非核心线程就会销毁。
unit:空闲时间单位
workQueue:任务队列
threadFactory: 线程工厂
handler:拒绝策略。目前jdk提供四种拒绝策略,一般默认的是抛出异常Abort这种,一般我们需要自己定义策略,根据不同的业务需求进行不同的操作,比如打印错误日志、将任务保存到kafka或者MQ、也可以将数据保存到redis或者数据库。四种拒绝策略分别是
Abort:抛异常Discard:扔掉,不抛异常DiscardOldest:扔掉排队时间最久的CallerRuns:调用者处理服务
注意:线程池在阿里的开发规范上建议不使用jdk自定义的四种ThreadPoolExecutor,建议自己根据不同的业务场景自定义线程池。比如我们可以实现ThreadFactory接口,自定义newThread方法,方便线程的管理以及问题的回溯。
线程池的种类
在jdk中提供了一些默认的线程池实现,主要有四种。它们的生成方式是封装在一个专门的线程池工具类中,叫做Executors,它可以看作线程池的工厂。
SingleThreadPool
单线程线程池,只有一个线程工作,保证扔进去的任务是顺序执行的。为什么会有单线程线程池呢?第一是有任务队列,保证任务按顺序执行。第二是可通过线程池管理线程的生命周期。
1 | public static ExecutorService newSingleThreadExecutor() { |
CachedThreadPool
可缓冲线程池,cachepool核心数是0,最大是Integer.MAX_VALUE,队列使用的是SynchronousQueue(这是一个阻塞调用者的队列),keepAliveTime=60s,工作原理为当来第一个任务时,会new Thread,之后的任务会校验是否有线程没在忙,没有的话就来他处理,否则再new 一个,处理完之后60s销毁。
1 | public static ExecutorService newCachedThreadPool() { |
FixedThreadPool
固定线程池,fixedpool核心数和最大线程数是相等的,通过传参传入,队列使用的是无界队列,keepAliveTime=0s。工作原理为我就指定了最多工作的线程数为这么多。
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
那么,CachedThreadPool和FixedThreadPool应该怎样使用呢?根据当前业务场景评估任务量以及平稳度,如果是忽高忽低,在保证任务进来之后会马上处理,不会堆积的情况下,可使用CachedThreadPool。如果评估任务来的是平稳的,数量也有一定的范围,可使用FixedThreadPool。
ScheduledThreadPool
定时任务线程池,核心数自己定义,最大数为Integer.MAX_VALUE,队列为DelayedWorkQueue。他提供了定时任务的实现机制.
1 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
可通过调用scheduleAtFixedRate方法间隔多长时间在一固定的频率上执行一次这个任务。该方法有四个参数,第一个是任务,initialDelay表示开始执行是延迟的时间,period表示间隔时间,unit表示间隔时间的单位。
1 | public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, |
总结
至此,线程池的基本概念就就讲完了,稍微总结一下:
- Callable类似于Runnable,但是有返回值,并且call方法还有可能抛异常
- Future是用来储存任务执行完的结果的
- FutureTask的本质是Future加上Runnable,即可以执行又能存结果,可以使用CompletableFuture管理多个线程的结果。
SingleThreadPool只有一个线程的线程池CachedThreadPool有弹性的线程池,只要没闲着的,就来一个启动一个FixedThreadPool固定了线程池的线程数ScheduledThreadPool线程池主要为了执行定时任务的
在我们实际开发中,一般都是自定义线程池,但是如果不了解原理的话,很容易滥用,导致一些系统运行缓慢甚至崩溃的问题。为此,分析源码的文章就留着下篇了。